
Spotify – How data is used to enhance your listening experience.

How Spotify uses Big Data to enhance its users’ experience. What are some potential problems that they might face with?
Overview
Spotify has long been focused on improving user experience as much as they can, and with their increasing focus on podcast investment, it is reasonable to assume that we will see even more enhancement of user experience.
Big data and data analytics has played a huge role in improving user experience. The core feature has been Spotify’s “Discover” feature, launched in 2012, which made new listening suggestions to users. Eventually, this became a “Discover Weekly” feature that provides users a personalized playlist every week composed of songs that the user has not heard and should align with the user’s taste. Within the first 5 years, Spotify users spent over 2.3 billion hours streaming “Discover Weekly” playlists. Not only has this created value for the users, by allowing them to discover new music, but it also allowed several artists to break into international markets.
Using Big Data to create value
One of Spotify’s funnest feature is “Wrapped”. Every December, “Wrapped” gives users a roundup of their favourite or most listened to song/artist of the entire year. “Wrapped” also lets users know if they were in the leading 1% of an artist’s most loyal listeners. This information is presented using data visualization to create a personalized story to all users. Spotify creatively encourages user engagement with “Wrapped” by issuing users with badges. For example, if a user’s playlists gained a number of new followers, they can be awarded with a Tastemaker badge. If a user listened to a hit song before anyone else, they are issued with a Pioneer badge.

Perhaps Spotify’s most impressive piece of engineering is its use of convolutional neural networks (CNN). Using CNN, Spotify analyzes raw audio data such as the song’s BPM, musical key, loudness, etc., to classify songs based on music type and further optimize its recommendation engine.
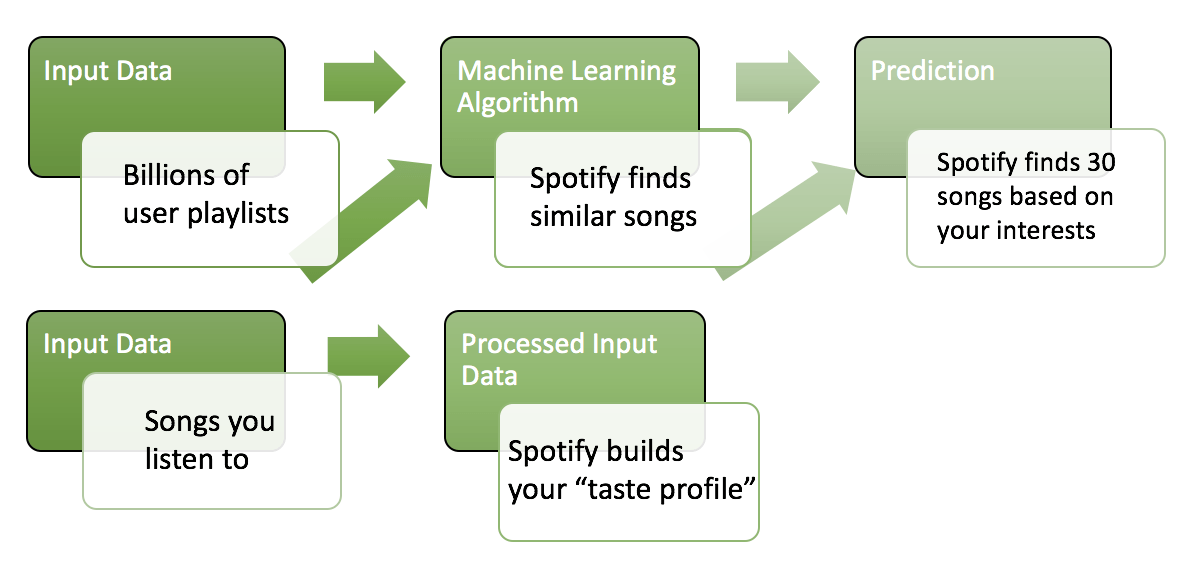
If Spotify can identify what specific musical attributes make a user like a particular song, their recommendation engine would reach completely new heights. However, I think that would be too much of a tall order.
What type of investments and process put that asset to use, and creates value for the company?
In January 2021, Spotify was granted a patent for speech recognition technology that would allow them to capture audio to more accurately identify the listener’s mood. More specifically, Spotify will be retrieving content metadata from the user’s voice and background noise. This metadata helps determine attributes such as age, gender, accent, which can help indicate the user’s emotional state. The next step is to classify the user’s emotional state which, presumably, helps make a better instantaneous recommendation.
Furthermore, the patent filing mentions another, more basic, approach of determining user emotion. Information such as intonation, stress, rhythm, are used to label user’s speech as “happy, angry, afraid, sad or neutral”.
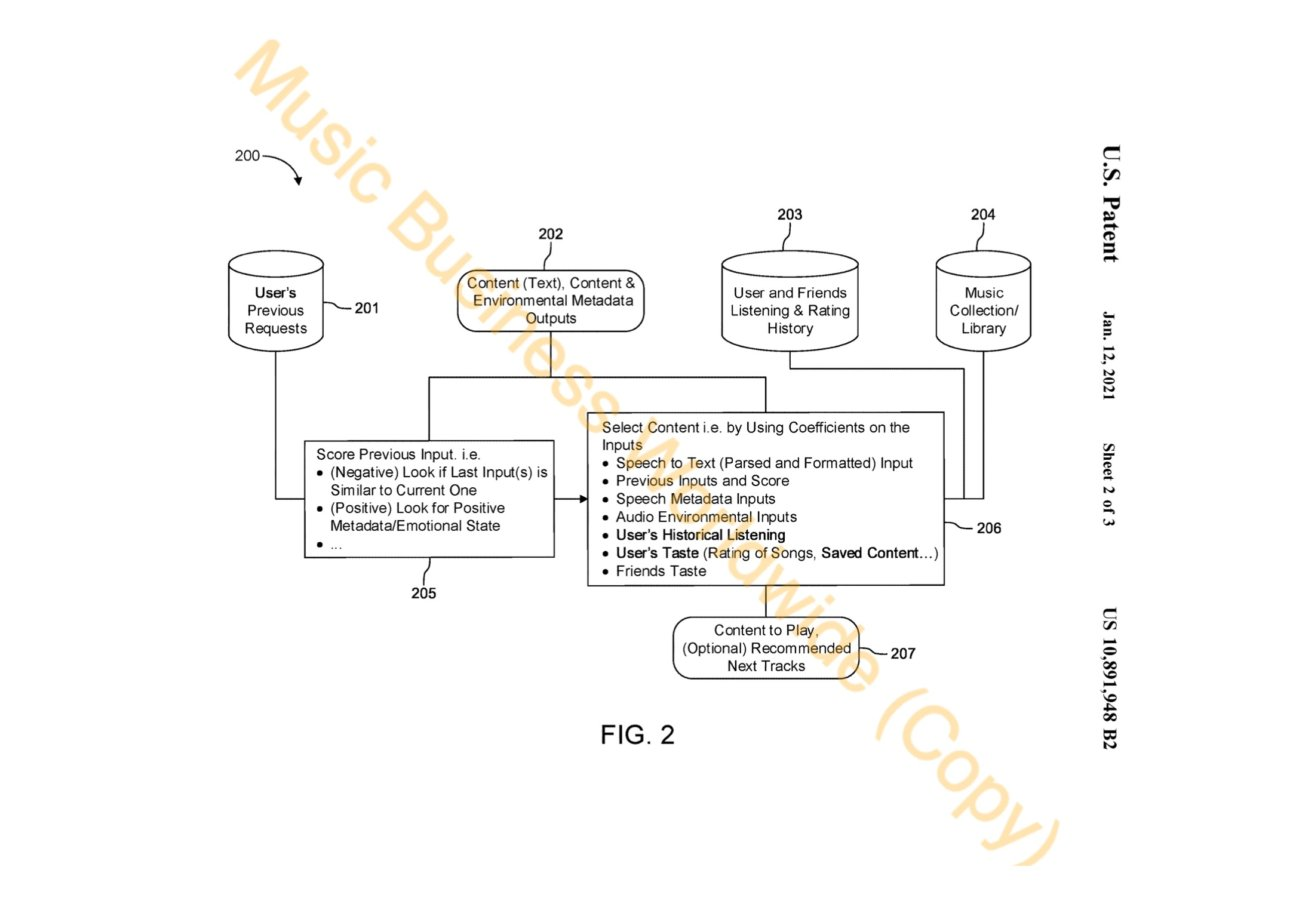
The figure above demonstrates this process. It shows that once all of the metadata is extracted and analyzed, and previous requests, listening and rating history of the user and friends, new content is recommended.
What challenges and opportunities do you anticipate for the company in the near term?
In the near term, I suspect Spotify will receive less return from their investments into big data and analytics as well as recommendation algorithms. I think it is vital for Spotify to develop new products, which they have done, so far, given their investments into podcasts. However, even with podcasts, a market that is becoming more and more saturated, I believe there are big limitations to what big data can provide to Spotify. I think the roles of recommendations is arguably less important in the podcast world because podcast content is much longer than any single song, so users take longer to digest podcast content.
Other sources:
Thank you for the post, Alan. I believe the patent for the voice recognition technology is both promising and concerning. From Spotify’s perspective, it can significantly help tailor the content suggested to users. Nevertheless, I believe it could give Spotify too much power to influence the emotional state of the user. Spotify could have an incentive to manipulate the user’s emotions to encourage them to continue listening to content on the platform. This could imply playing on a person’s depressive state to keep them listening to content that can further deteriorate that emotional state.
Sebastiano, this is a great point! There is always a fine line with these technologies, and you highlight an important way in which Spotify’s technology could be leveraged to exacerbate users’ emotional states.
From your perspective, how might you ensure Spotify’s responsible use of this technology? Do you think policy is ideal, or best practices? How would you like to see Spotify navigate its responsibility towards user mental health vs. maximizing streams?
Thank you for this interesting post, Alan! The improvements in Spotify’s recommendation algorithm have been impressive (anecdotally, I remember it almost being a meme how bad their recommendations were a few years back). I fully agree with your analysis that Spotify urgently needs to build new product/functionalities to distinguish themselves from their competitors as, in contrast to the movie/ tv show streaming ecosystem, all the music streaming providers offer the same music. Spotify Wrapped is a great success in that regard since they managed to turn into a cultural event where people actively share and send around screenshots of their Wrapped. Users of other platforms cannot participate in the fun and social interaction.
Alan, great minds think alike! What a wonderful piece!!
I’d love to hear more about your perspective regarding the limitations of big data with podcasts. I think big data is very impactful when it comes to podcasts. Most podcasts on Spotify contain ads within the podcast, which is a huge source of revenue for both Spotify and the podcasters themselves. Additionally, I think that since podcasts are a bigger commitment, there is less ‘multi-homing’ in the sense that most users may only listen to a handful of podcasts, compared to the thousands of songs. This might be a bit of a stretch, but I’d be interested in hearing your thoughts on this!
Hey Maxwell!
Thanks for your comment. When I was writing about the limitations of big data with podcasts I definitely made a few assumptions that are up to debate. My first one was that because podcasts are longer than individual songs, people won’t be listening to as many podcasts as songs, thus prediction would be made more difficult. Secondly, I assume that listeners are not as obsessed about constantly discovering new podcasts like they are with new songs since podcasts are a bigger commitment. I think that makes sense? I’m not so sure so I guess we’ll discuss in class tomorrow.
You make a great point about big data allowing Spotify to place more personalized ads, that is a huge driver of revenue for them.