
Machine Learning in Drug Discovery
Machine learning has the potential to disrupt the drug discovery process, Pfizer has been dipping its toes in the water by collaborating with machine learning service providers, but is it enough?
Drug discovery is costly and risky. In 2016, the total R&D spending of pharmaceutical companies surpass $70 billion [1]. The average drug development process holds an estimated cost of $2.6 billion and takes 10 to 15 years to develop a single drug [2]. Pharmaceutical companies examine numerous compounds to find the ones that may act on a specific pathway. Only the compounds that pass early tests for toxicity and metabolizing have a potential to move on to clinical trials. Less than 12 percent of drugs that enter clinical trials will eventually be approved [2].
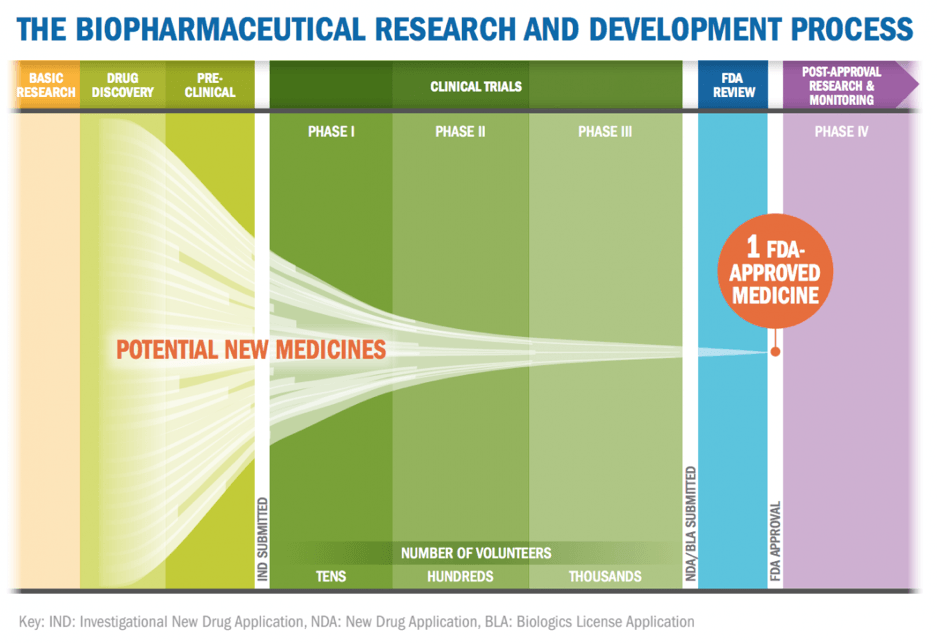 Machine learning is emerging as a potential solution to approach this process with more efficiency and lower cost. The idea of computer-aided drug discovery is not new. But the recent explosion of data available, rapid development of graphics processing units (“GPU”) and cloud-based computing has made deep learning and big data modeling possible [3]. Machine learning can be extremely helpful in the following aspects: more efficient screening of new compounds, optimizing molecular designs against multiple property profiles of interest, and identifying synthetic routes to realize the composition.
Machine learning is emerging as a potential solution to approach this process with more efficiency and lower cost. The idea of computer-aided drug discovery is not new. But the recent explosion of data available, rapid development of graphics processing units (“GPU”) and cloud-based computing has made deep learning and big data modeling possible [3]. Machine learning can be extremely helpful in the following aspects: more efficient screening of new compounds, optimizing molecular designs against multiple property profiles of interest, and identifying synthetic routes to realize the composition.
Pfizer: Dipping Toes in The Water
In December 2016, Pfizer announced a collaboration with IBM that will use IBM Watson for Drug Discovery platform in the pharmaceutical giant’s immune oncology R&D.
The IBM Watson for Drug Discovery is a cloud-based platform that utilize deep learning, natural language processing and other cognitive reasoning to support researchers in finding hidden connections in science. The platform has been fed with more than 25 million abstracts, more than 1 million full-text journal articles and 4 million patents in order to streamline the drug discovery process. By contrast the average researcher reads between 200 and 300 articles in a given year [4].

Pfizer expects to use the platform to analyze massive volumes of disparate data sources, including publicly available clinical and scientific data as well as Pfizer’s proprietary lab data, to discover immune-oncology therapy candidates and the possible combination of them [5].
In addition to the collaboration with IBM, in 2018, Pfizer launched new collaboration with the Chinese tech startup XtalPi for small-molecule modeling. According to their joint announcement, Pfizer and XtalPi are currently collaborating in crystal structure prediction and screening—using computer models to determine the potential molecular stability of an organic compound—and are looking to advance their work in drug design and solid-form selection [6].
All in AI?
Pfizer’s approach to AI is a cautioned experimentation, rather than a full-on embrace. Pfizer is not alone among big pharmas in adopting this strategy. Roche (Genetech) announced collaboration with GNS Healthcare, Sanofi collaborates with Exscientia, GlaxoSmithKline signed a similar deal with Exscientia and Insilico Medicine. Their strategy begs the question of whether they have done enough. If machine learning has the potential to be the disruptive technology in pharmaceutical industry’s drug discovery process, market leaders like Pfizer can only solve the “innovator’s dilemma” through founding or acquiring an independent subsidiary and equipping it with the necessary resources [7].
Machine learning has the unique feature of positive reinforcement—the more data one has, the better algorithm can be developed, the better one’s algorithm is at predicting results, the more customers it attracts with even more data available. Big pharma’s collective inertia to develop their own machine learning platform leads to the concentration of data in a handful of tech startups to whom the big pharmas outsource the work. Pfizer, and other market leaders, might be breeding a potential competitor in the high potential space of growth.
In the medium term, Pfizer needs to establish its own machine learning analysis team in house or make acquisition of startups in the space. Indeed, machine learning’s application in drug discovery has not been proven clinically, therefore, a strategy of “All in AI” involves considerate amount of risk. But if Pfizer wait until full proof of machine learning’s superiority, what is a cue today might well turn into a tiger to bite off Pfizer’s market dominance.
Questions Remain
Despite all the hype and hope machine learning has offered, drug discovery has never been and certainly will not be an easy field. At the heart of any machine learning application is the quest for high-quality data to train the algorithm. However, many of the existing scientific research data sets likely have high noise levels and may have inconsistent standards, impacting the comparability across different experiments or laboratories. New challenges to deal with heterogeneous data sets and experiment conditions remain unsolved. Will they block the application of machine learning in drug discovery? How should market leader like Pfizer position itself against this particular challenge?
 (765 words)
(765 words)
[1] Frost & Sullivan, “Influence of Artificial Intelligence on Drug Discovery and Development,” July 18, 2018.
[2] Pharmaceutical Research and Manufacturers of America, “2016 Biopharmaceutical Research Industry Profile,” http://phrma-docs.phrma.org/sites/default/files/pdf/biopharmaceutical-industry-profile.pdf.
[3] Zhang, Lu et al, “From Machine Learning to Deep Learning: Progress in Machine Intelligence for Rational Drug Discovery,” Drug Discovery Today, Volume 22, Issue 11, November 2017, Pages 1680-1685, https://doi.org/10.1016/j.drudis.2017.08.010.
[4] Van Noorden R, “Scientists May Be Reaching a Peak in Reading Habits”, February 3, 2014, http://ibm.biz/BdrAjS.
[5] Pfizer, “IBM and Pfizer to Accelerate Immuno-Oncology Research with Watson for Drug Discovery,” December 1, 2016, https://www.pfizer.com/news/press-release/press-release-detail/ibm_and_pfizer_to_accelerate_immuno_oncology_research_with_watson_for_drug_discovery.
[6] XtalPi Inc., “XtalPi Inc. Announces Strategic Research Collaboration with Pfizer Inc. to Develop Artificial Intelligence-Powered Molecular Modeling Technology for Drug Discovery,” Feburary 8, 2018, https://www.prnewswire.com/news-releases/xtalpi-inc-announces-strategic-research-collaboration-with-pfizer-inc-to-develop-artificial-intelligence-powered-molecular-modeling-technology-for-drug-discovery-300644351.html.
[7] Christensen, Clayton M, “The Innovator’s Dilemma: When New Technologies Cause Great Firms to Fail,” Boston, MA: Harvard Business School Press, 1997.
Hi Stacy,
I very much enjoyed your piece, which was well-written. A few points to consider:
1. The $2.6 billion figure you have cited is perhaps exaggerated. Would refer you to Jerry Avorn’s excellent Perspective in NEJM (“The $2.6 Billion Pill — Methodologic and Policy Considerations”, 2015) on the matter. Half the figure comes from a cost of capital estimated at 10.6%!
2. The data inputs mentioned vary widely in nature. I would be keen to hear more about which applications (e.g., designing new molecular entities versus identifying the most promising investigational compounds synthesized to date) may be most impactful in the near future.
3. Difficulties with synthesizing published data – which are often quite heterogenous in presentation and quality – aside, what are your thoughts on potential shortcomings of machine learning secondary to known publication bias?
Thanks,
Vinay
This piece provides a fascinating look into machine learning’s potential impact on pharmaceutical development. I think you did an excellent job situating Pfizer’s approach as an intermediate investment in the technology and forced us to consider if it was sufficient.
I wanted to raise 2 thoughts for you to consider:
1. You mentioned that it might be for pharmaceutical companies to partner with start-up AI companies out of fear of them becoming future competitors in the space. You concluded that it would be better to develop AI capabilities in-house or else acquire a start-up with expertise in the area. I would argue that’s one way in which Pfizer’s current strategy, of partnering with IBM, makes perfect sense. No matter how much data Watson accumulates, or how adept it becomes at developing drugs, there is very little chance that IBM will enter the pharmaceutical development space! So perhaps one solution is simply partnering with larger organizations.
2. You finished your article by posing the question of integration. How can these platforms aggregate data from clinical trials and scientific reports when the conditions, the methods of collection, and the numbers of participants lack consistency? One suggestion might be a system that uses weights for each data-set depending on the question you’re considering. For example, if I’m looking to develop a drug that treats sleep apnea in 15-25 year olds, I can weight the results of studies differently depending on their number of participants, the age range and the credibility of the methodology. The major problem with this, of course, is that it would still require a human to input these weighting factors based on their discretion.
Thanks,
Gabe
I agree that the heterogeneity of the data will continue to pose challenges for the use of machine learning in drug discovery. As this is an issue that will be difficult and inefficient for a single company to solve, and I wonder if a company like Pfizer could organize a consortium of companies to jointly tackle this issue. To counter some business and legal risks, they would potentially start with the existing alliances or open innovation programs that they have with other companies (rather than starting a completely new program)