
Watson: IBM’s AI as a Service

Inside IBM's multi-billion dollar AI as a service business that started with a group of three researchers almost 15 years ago
In order to differentiate themselves in the lucrative cloud business, big tech firms have invested significantly in value-added services, most notably in AI as a service. Within this space, IBM has built a competitive advantage in the field of natural language understanding through its development of proprietary knowledge base systems. This blog helps us better understand this key resource that is at the heart of IBM’s differentiation and how IBM has changed organizationally to support its growth through build, borrow, and buy initiatives.
What is a knowledge base system?
A knowledge-based system is a set of rules and cases created and curated by humans to train machines. Knowledge-based systems are particularly helpful in cases requiring deep industry expertise such as health care where insights from physicians can be incorporated in clinical decision-support systems [1]. Below is a sample of how a knowledge-based system is constructed through natural language by enabling the AI to recognize that two entities such as people and organizations are co-related to each other through a set of rules [2]. The first rule tells the computer that a person and a location are co-related if the words “born”, “born in” and born at” exist in between their references.

Source: https://github.com/IBM/watson-document-co-relation/blob/master/configuration/sample_config.txt

Creating a Knowledge Base
We examine how IBM created its knowledge base through the lens of theory – namely the build, borrow, buy framework in Corporate Strategy.
Build: According to their company presentations, IBM now has over 1000 researchers working on AI, which a field which represents 1/3 of their research division. IBM displayed the deep knowledge base that some of these researchers had created in having its supercomputer Watson compete and win against top players in the game show Jeopardy. Watson was built on the work of 20 researchers over three years and 200 million pages of information. Watson represented the next level of super-computing capabilities after its predecessor “Deep Blue” beat then world chess champion Garry Kasparov, and IBM moved quickly to commercialize its “grand challenge” winner. In late 2011, IBM added 107 staffers to Watson, mostly in the fields of machine learning and natural language processing, just three months after the Jeopardy win in part to continue building its knowledge base [3].

Borrow: In 2017, IBM launched a 10-year, $240 million partnership with MIT to create a joint Watson AI lab. Over 100 AI scientists, faculty, and students will continue to build Watson’s knowledge base across several areas including cybersecurity and health care [4]. One area of improvement is expanding the applicability of its knowledge base by teaching AI to generalize and apply its knowledge from one domain to another. Another opportunity lies in teaching the AI on where to focus its attention given the vast amount of data it may surface from its knowledge base [5].
Source: http://news.mit.edu/2017/ibm-mit-joint-research-watson-artificial-intelligence-lab-0907
Buy: According to company documents, IBM’s strategy for acquisitions has focused on buying data sets and domain expertise to build its knowledge base and launch in Watson offering in specific industry verticals. In 2015, for instance, IBM acquired the healthcare intelligence company Explorys, which had built a large clinical dataset of over 100 million electronic medical records that could be fed into Watson’s knowledge base. Following the acquisition, IBM launched its new Watson health unit, which aims to understand connections between diverse health datasets to find new data-driven applications to promote wellness [6].

Source https://www-03.ibm.com/press/us/en/pressrelease/46585.wss
A year after its acquisition of Explorys, IBM acquired Promontory to launch its Watson Financial Services platform. Promontory is illustrative of how a knowledge base can be improved by acquiring deep expertise in addition to data. Promontory was an advisory services leader in regulatory compliance. Through its acquisition of its 600 professionals, IBM was able to translate their human knowledge into sets of rules and cases to train Watson to make sense of 300 million pages of financial regulation [7].

Source: https://www-03.ibm.com/press/us/en/pressrelease/50599.wss
Sample Application
IBM’s knowledge base is offering as AI (Watson) as a service. Integrated into its broader cloud offering, IBM allows its cloud users to leverage its knowledge base to automatically analyze and understand unstructured data through an API. Each time the customer calls the API, she pays a small fee of a fraction of a cent. One application of an API call is visualized below. Here the user can ask a weather-related question and Watson will leverage its knowledge system to classify whether the question more closely relates to temperature or conditions [9]. This type of classification is used, for instance, in automated customer service software to direct a customer’s call to the most relevant company support agent.
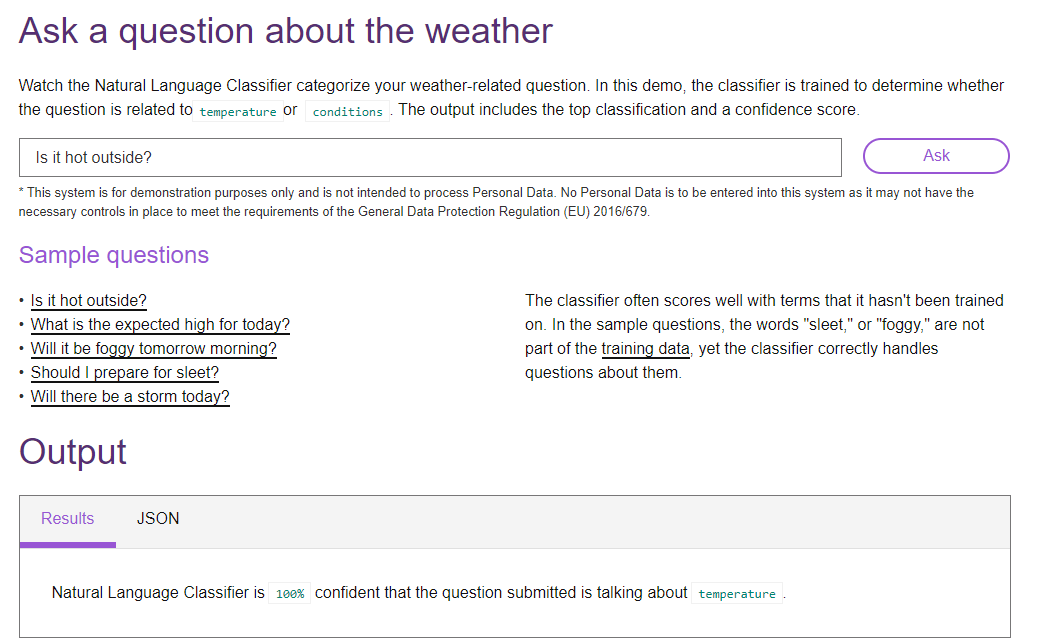
Source: https://www.ibm.com/cloud/watson-natural-language-classifier
IBM has focused on differentiating itself in the AI as a service space by growing a large knowledge base through a combination of large datasets, machine learning, and human insights that have been translated into detailed, machine readable sets of rules and cases. IBM’s large and continuing investments in this knowledge base serve as a barrier to entry in natural language understanding for other large tech firms. Having built a horizontal platform in Watson, IBM’s opportunity is to continue to penetrate different verticals. One of its areas of growth is in making it more friction-less for a user to further customize and incrementally train Watson based on their own use case.
References
[1] https://searchcio.techtarget.com/definition/knowledge-based-systems-KBS
[2] https://github.com/IBM/watson-document-co-relation/blob/master/configuration/sample_config.txt
[4] http://news.mit.edu/2017/ibm-mit-joint-research-watson-artificial-intelligence-lab-0907
[5] http://mitibmwatsonailab.mit.edu/research/projects/
[6] https://www-03.ibm.com/press/us/en/pressrelease/46585.wss
[7] https://www-03.ibm.com/press/us/en/pressrelease/50599.wss
[9] https://www.ibm.com/cloud/watson-natural-language-classifier
Great article Sarkis, when I worked at Walmart I was an early participant of “company-wide hackathons” that promoted the use of new tech to improve the customer experience. My team and I had an idea that would leverage Watson to create instant search results (like Google’s search bar) for the Walmart.com website. While we were not selected to move to the final round, we learned that Watson’s API is actually pretty easy to implement with the right foundations in place. Because a lot of Walmart’s code was written in Cobol we had some trouble trying to marrying the API with the source data, but our result was a very rudimentary “AI” embedded search bar. If you are interested in building that on campus at Hi Labs let me know!
This was a great overview of the Watson project. I was familiar with the name of course, but I did not realize that the project spanned so many different initiatives and was so heavily funded. I was not aware of the partnership with MIT either. Have you ever participated in any Watson-related events at MIT? With so many different verticals, I wonder how much Watson all the different models have in common. In other words, is there a “core”, or “kernel” that all the different models share, something proprietary perhaps? How much of the code base is open-source?
IBM is kind of the old guard in the AI space with the high profile jeopardy application. They haven’t seemed to find much success in broadening the application area for the technology as one might’ve thought. At least in the healthcare space, the Watson-MD Anderson partnership ended in complete disaster. It seems like it is often hard to tell when there is a legitimate usage for these general AI solutions vs when it is just a marketing ploy.
This is a really interesting read! Initially I had only heard about Watson from the jeopardy and chess victories it had against top human players. Recently through I was reading about how Watson is used in the education sector by creating the Watson virtual tutor, to have personalised conversations or instruction with different students.
Looking forward to looking at what other use-cases Watson will be trained in.