
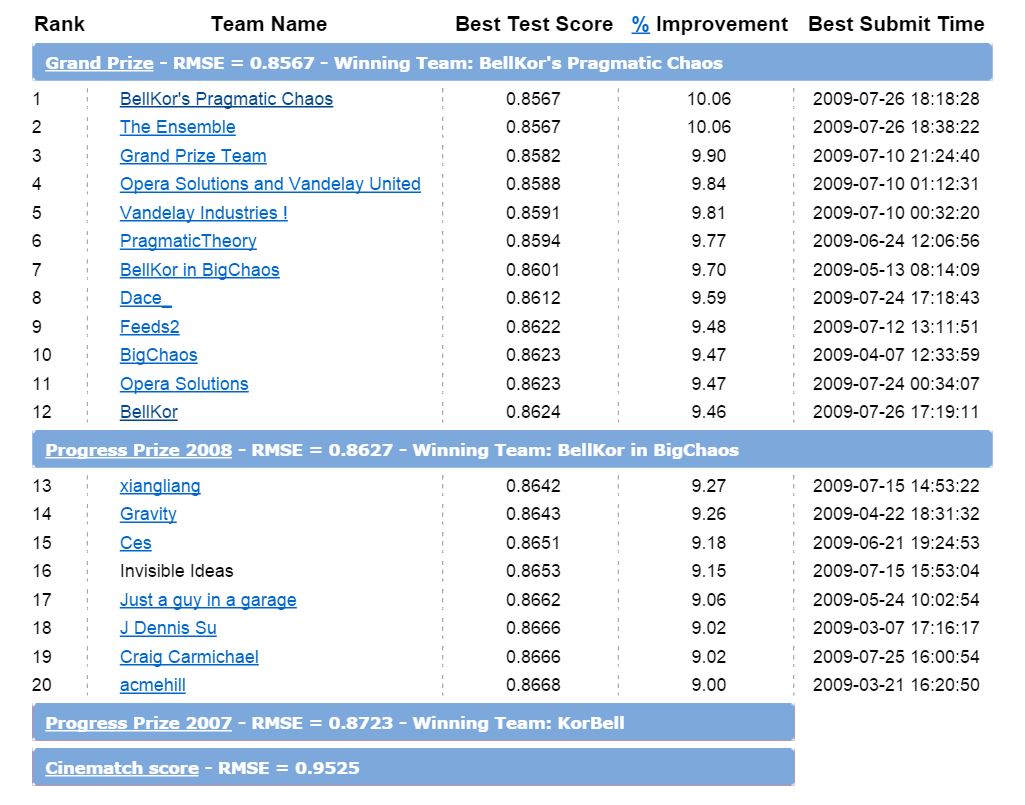
The Netflix Prize: Crowdsourcing to Improve DVD Recommendations

Netflix utilized crowdsourcing to develop innovative solution to improve its recommendation engine by 10%. The 3-year Netflix Prize attracted 44,014 submissions, and was ultimately won by a team that had combined algorithms after the second year of the contest, proving that you can crowdsource a crowdsource.
In 2006, Neflix launched the Netflix Prize, “a machine learning and data mining competition for movie rating prediction.” Netflix hoped the $1 million prize would encourage a range of algorithmic solutions to improve the company’s existing recommendation program, Cinematch, by 10%. Cinematch used “straightforward statistical linear models with a lot of data conditioning,” and served two major purposes: as a competitive differentiator by recommending unfamiliar movies to customers, and more importantly, enabled Netflix to reduce demand for blockbuster new releases and improve assets turns of all DVDs in inventory.
Project Scope: Netflix defined the project scope as a 10% reduction of the “root mean squared error” (RMSE) from Cinematch’s existing 0.9525, and set a series of guidelines for competition participants. Netflix provided a dataset containing 100 million anonymous movie ratings for participants to test their algorithms.
2007 Progress Prize: In 2007, the BellKor Team, comprised of three employees from the Statistics Research group in AT&T labs, achieved an 8.43% improvement over Cinematch, and were awarded the first of two $50,000 Progress Prizes. The team spent nearly 2,000 developing a final solution that contained 107 algorithms and achieved a RMSE of 0.8712. Netflix engineers investigated the source code (a requirement for the prize), and identified the two best performing algorithms (of the 107): Matrix Foundation (also known as Singular Value Decomposition (SVD)) and Restricted Boltzmann Machines (RBM). “A linear blend” of the two algorithms were ultimately put to use in Netflix’s recommendation system, but the company set a goal of 1% improvement over BellKor’s solution to receive the 2008 Progress Prize.


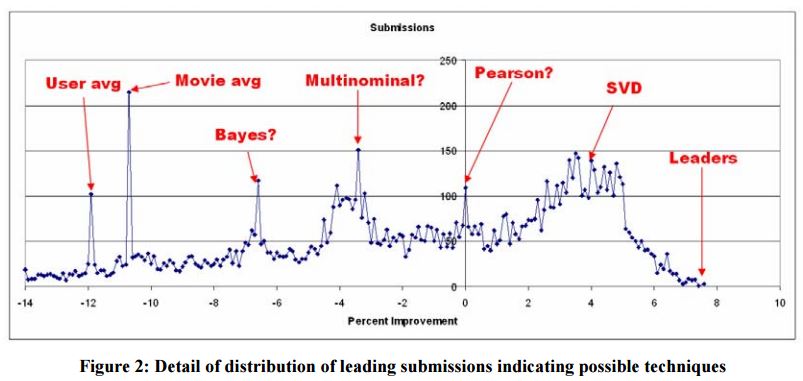

When it was an independent team, Pragmatic Theory, discovered that the number of movies rated by an individual on an given day could be used as an indicator of how much time had passed since the viewer watched the movie. They also tracked “how memory affected particular movie ratings.” (ed. note: unclear how this was done). Although this discovery was not particular successful on its own at achieving the >10% improvement, when combined with BellKor’s algorithms, it gave the new team a slight edge over the competition.

Thank you for the post! I am always amused by Netflix and what’s happening to the business. They were successful in disrupting Blockbuster and a lot of credit to their business model actually lies in their superior movie recommendation algorithm. I had never realized the way they went about to refine the algorithm and make it so defensible that others could not spend the dollars to do themselves. Clearly they have demonstrated a lot of innovation in doing so! Though now going forward I am curious to see how much the algorithm can help them differentiate given that now video is now moving to a OTT model and that players like IMDB have a much larger database that Amazon Video has access to with their videos. Netflix needs to innovate again if it wants to survive and do something which other players cannot. May be the answer lies in how they can innovatively leverage the crowd again so that what they did to Blockbuster does not happen to them.
Great example Noah. I always thought this was such a brilliant move on Netflix’s part to improve their product. However, I think this is an example where casting a wide, crowd-sourced net can create some unintended consequences. Apparently the initial contest caused some privacy concerns that resulted in a class action lawsuit and the cancelation of the second contest (http://www.wired.com/2010/03/netflix-cancels-contest/). Additionally, my understanding is that not all of the contest innovations were used because of the engineering costs associated with implementation (http://arstechnica.com/gadgets/2012/04/netflix-never-used-its-1-million-algorithm-due-to-engineering-costs/)
Great post! Really interesting to see examples of crowd-sourcing very specific requests. I always like to think about whether the incentives to participate are optimized. Do you think if the award was bigger, Netflix would have gotten a better outcome? If it was smaller, would the outcome have been significantly worse? Always interesting to debate, and your blog really made me think of this.
Can’t wait to read your next post!