
Real-life ‘Minority Report’

PredPol, crime prediction service
People post photos every day on Facebook, read articles on their smartphones, and pay by credit card. It seems to be a meaningless everyday life, but every single action is accumulating data. It is the so-called “big data” age. The artificial intelligence (AI) that is going on now is getting more advanced thanks to big data.
Data analysis is used not only in our real life but also in the public domain. To predict the crime that is directly related to our safety.

In Los Angeles, Los Angeles Police Department(LAPD) uses big data to predict crimes. The crime prevention platform, PredPol predicts when and what type of crime will occur in the areas. Police can use this to efficiently deploy policemen, which can reduce costs and increase crime prevention effectiveness.
PredPol predicts the types of crimes that occur in each region.
This prediction service, developed by Dr. Jeff Brantingham, anthropology professor at UCLA and Dr. George Mohler, mathematician at Santa Clara University, analyzes historical data from past crimes and predicts future crime types and regions. Predpol does not predict criminals like the movie ‘Minority Report’. However PredPol analyzes the types of crimes that have occurred, where they occurred, and date and time data to predict future crimes.
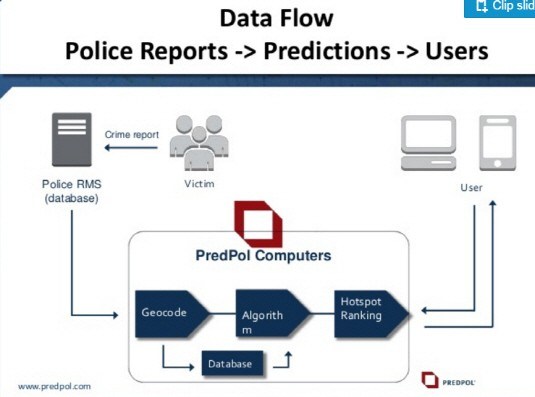
PredPol receives data from the police authorities’ RMS (Records Management System), which collects crime types, locations and times. The PredPol computer informs you once a day about the type of crime, place, and time that you expect to get through this data.
PredP0l updates the program every time when a new crime occurs, making new predictions every day. The prediction is so specific that it tells what crime will occur in a square of about 500 feet x 500 feet. Also it ‘re-learn’ all the crime patterns every 6 months. This allows the system to better understand and predict new crime patterns. In fact, in the United States, after the introduction of PredPol, theft crime was reduced by about 13% and robbery crime by 22%.
PredPol not only uses advanced mathematics and computer-learning techniques, but also studies the behavior and psychology of criminals. It understands a big crime or similar pattern of crime patterns occur after small crimes accumulate. It is to collect and analyze the cases of minor crimes and to predict at what point to go beyond the limit and into the big case.

PredPol also understands the similarity between crime and earthquakes. Earthquakes occur intensively in fault zones, and small earthquakes occur after a big earthquake. Similarly, there are crimes where there are many crimes, such as near bars.
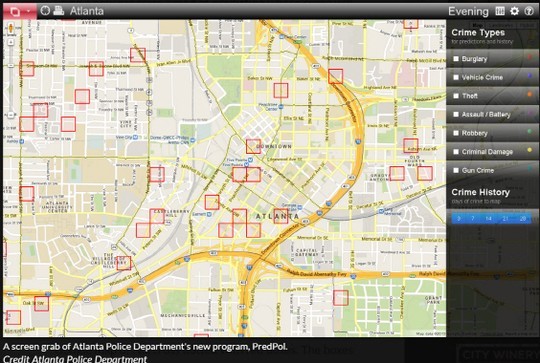
Using these insights and about 13 million crime data accumulated for 80 years in Los Angeles, Predpol calculates the crime rate for each region on the map.
There was a system that predicted crime in the past. However, PredPol’s accuracy is much higher than the old one that predicted by probabilistic experimentation on the map where the crime occurred.
PredPol says crime prediction service can increase the predictability of crime by combining the data it has accumulated over time, analyzing criminals’ behavior patterns, and advanced mathematics. Unconditional “data” is not the only solution for data analysis. Data and a variety of intuition and insights must be combined to apply more appropriate algorithms and produce good results. This case seems to illustrate such an example.
That is super interesting, Seunghyun!
One thing this makes me wonder – Bruce Schneier is an HKS professor and security professional. He says that the risk with deep learning and big data is that they could easily become a laundering tool for bias. How can the predpol system make sure it is not based on data that is biased prematurely against a certain demography? The risk of misunderstanding causation and correlation seems huge here.
Thanks Seunghyun, very interesting and cool technology.
Agree with Yuval on the risk of bias. And human beings are complex, I wonder how the technology is able to capture the different parameters and factor that into the model. What if human judgement (art) contradicts with the data results (science)?
How transferable the algorithm would be across demographics?