
FiveThirtyEight and the Big Data Fail: Election 2016

Statistics junkie Nate Silver uses data to predict everything from internet slang to Oscar winners to the US Presidential election.
Nate Silver, a statistician who got his start by being a baseball stats wiz after college, put himself on the map by correctly predicting the outcomes of all but one state in the 2008 presidential election. Silver established his blog, FiveThirtyEight, to help quantify the qualitative – although he is best known for his sports and politics predictions, he tracks things as quotidian as usage of “haha” vs “lol” and predicting statistical likelihood of Oscar nominees to win by category. Silver is nothing short of a data junkie, and uses it to power his entire website.
FiveThirtyEight as a business operates similarly to many media enterprises, by offering content to users for free in exchange for advertising revenue. The blog was originally “transitioned” to the New York Times in 2010, and then re-sold to ESPN in 2014. These media properties used their own data to determine how to price and value advertising on FiveThirtyEight – indeed, in 2011 over 20% of the traffic to the NYT website was directly to view FiveThirtyEight.
But the secret sauce of the website is the statistically-based content, coined “data journalism” by ESPN during its acquisition. Silver seemingly gives away his statistical analysis for the low price of ad revenue, capturing less value than it could if it sold its data via a database or an API directly to businesses. He happily walks readers through his statistical thought processes, knowing that most of his readers are unable or unwilling to recreate the analyses themselves. In doing so, he creates a value creation moat around his content because he uses and weighs data in ways most people don’t think to do. As a result, most other journalists are unable to recreate the content on FiveThirtyEight, keeping it competitive as a media platform.
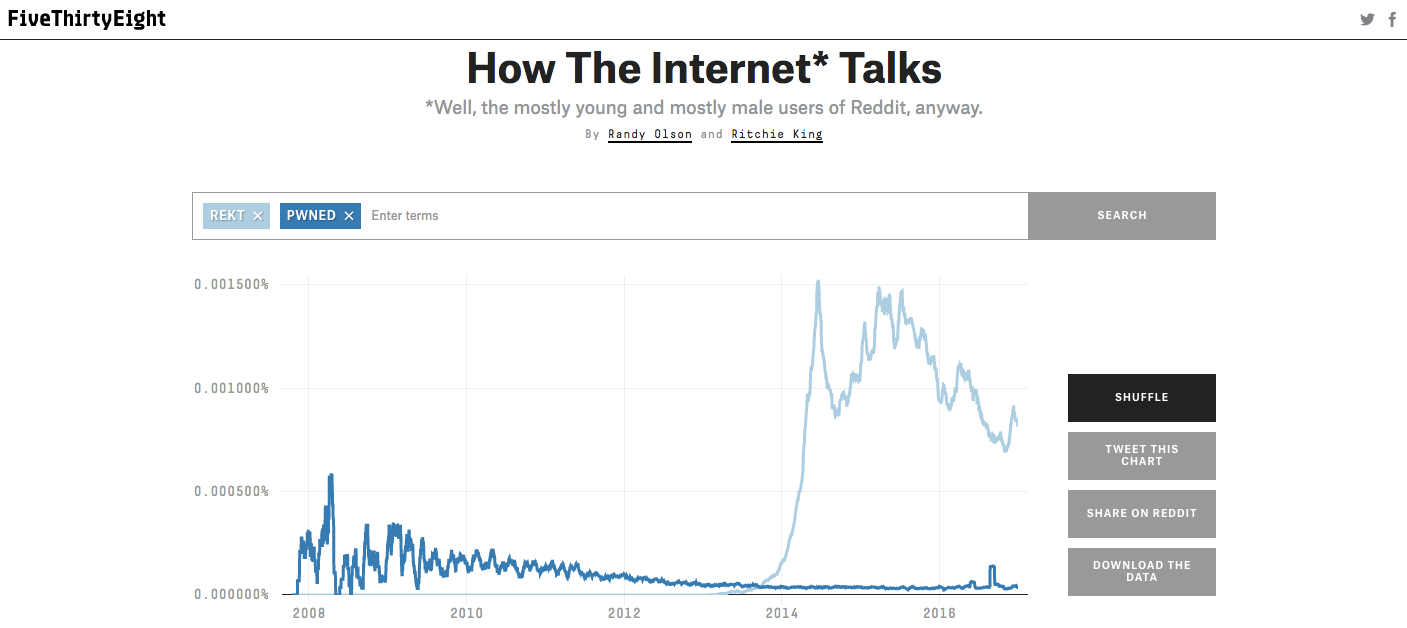
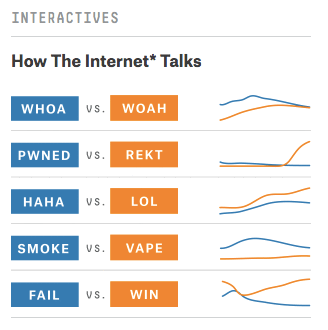
FiveThirtyEight hit its first major data gaff in the 2016 elections, proving that creating statistical models behind closed doors does not necessarily lead to the best outcome. As he had done in the 2008-2014 elections, Silver set out to predict first the outcome 2016 Republican Presidential Primary and then the results of the Presidential race. Unfortunately for Silver, the moat he had created meant that he was subject to only his own inputs, and not necessarily feedback from “the crowd.” Although Silver used a wide range of data: from gallup polls to election day weather forecasts, his data models missed the rise and triumph of Donald Trump.

The team at FiveThirtyEight were flippant about the idea of Trump becoming the nominee – writing articles like the one titled “Why Donald Trump Isn’t a Real Candidate, In One Chart”: “Trump has a better chance of cameoing in another ‘Home Alone’ movie with Macaulay Culkin—or playing in the NBA Finals—than winning the Republican nomination.” Although they gave Trump a bigger chance of winning than almost any other media source (~33%), they still missed the mark on the electoral college. Silver admitted that they missed, but blamed the third-party data sources that they were using to underly their model. Although Silver was able to successfully buck the trends in 2008 and 2012, he succumbed to the same problems as many other pollsters and forecasters in 2016 – he neglected to account for some bias and margin of error in the state-level polls.
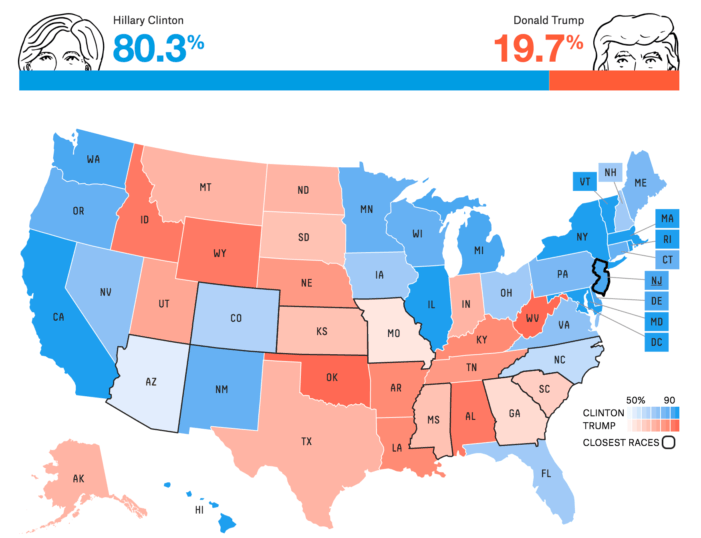
One of the biggest risks of combining a media business model with major statistical analysis as content is that when you are wrong in your data predictions, you are wrong in a very public fashion. Although FiveThirtyEight tried to hedge its position in the days leading up to and the days after the election, by touting that they were much closer than many other media outlets showing 85-99% likelihood for Hillary Clinton, Silver personally received pushback and ridicule for months following the election.
A takeaway for Silver and the FiveThirtyEight team is that centering a business around the results of your data can be risky if you do not allow others to access and use that data for other purposes. Perhaps Silver could have saved-face by selling the raw data directly to businesses, or allowing users to publicly maneuver his statistical analysis to get a better range of results. There is no silver bullet, but the combination of FiveThirtyEight’s value creation and value capture led to a problematic 2016.
Sources:
- https://gigaom.com/2013/03/10/how-a-bad-fantasy-baseball-team-turned-nate-silver-into-americas-top-data-nerd/
- http://www.telegraph.co.uk/news/worldnews/us-election/9662363/Nate-Silver-politics-geek-hailed-for-Barack-Obama-wins-US-election-forecast.html
- http://www.nytimes.com/2010/06/04/business/media/04silver.html
- http://www.adweek.com/tvnewser/nate-silver-sold-fivethirtyeight-to-espn/190290
- http://www.politico.com/story/2016/11/2016-election-worst-predictions-230806
- https://www.quantamagazine.org/20161108-why-nate-silver-and-sam-wang-are-wrong/
- http://www.alternet.org/election-2016/nate-silver-reveals-why-were-not-done-polls-after-trevor-noah-skewers-him-being-so
- https://fivethirtyeight.com/features/the-polls-missed-trump-we-asked-pollsters-why/
I agree Nate Silver took a lot of heat for not getting this right especially since he is seen as a data guru of sorts in journalism. However, his miss made me realize that maybe he shouldn’t be relying on third party sources for data inputs. We’ve all heard the phrase “garbage in, garbage out”. There are multiple theories and explanations behind why the polls were so off on this election, but if I were Nate, going forward I would want my own data that I collect and vet (especially for something as big as an election). Now I understand this is A LOT of work, but as you said, no one is doing the type of work in journalism that he is doing. Collecting his own data would only make his data inputs stronger. And since he is a vetted source and people respect him, he could sell that data to others as an unaltered raw data set that doesn’t have any biases.
I totally agree. I think Silver would do well to actually start his own polling company to generate his own data. Relying on third-party information for complex data models can be comprehensive, but risky. It’s an interesting business proposition for ESPN, but very much worth exploring if I were Silver.
I agree that FiveThirtyEight’s complete reliance on data makes their misfires very public (particularly when you set the bar extremely high, like they did in 2008 and 2012), and that’s very unfortunate. Because, like you mentioned above, despite their “gaff” they still did a much better job predicting the election (the general election that is) than almost all pundits and talking heads. On the morning of the election, FiveThirtyEight placed Trump’s chances ~30%, which is really not that low. Before the election, other media outlets were scoffing at how high of a chance Silver was giving Trump, and after the election they blamed him that the chances weren’t high enough. I’m much more sympathetic to Silver here, and consider this more of an imperfection of data/current polling methods (to Nupur’s point above), as opposed to a big fail.
Thanks for sharing! The failure of data and statistics in the recent presidential election is an extremely interesting topic.
While third party data made Silver miss the target, I’m not sure turning into a pollster is the solution. I believe that, inherently, the failure of data predictions in the recent election and the reason the data was so off was the public being unwilling to admit to others, and possibly to themselves as well, of the biases that drive their decision making process. Polling is eventually based on a very subjective decision by the polled: should they be frank?
A deeper question is possibly how can one reframe questionnaires to uncover underlying biases and real election decisions rather than a stated one, and by which creating a more reliable data set. Not sure if the data wiz is the person to peal away psychological barriers.
Ellen, great post. I appreciated all of the comments above, as well.
One of my key takeaways here is that this is a clear example of how data can reduce the probability of an incorrect prediction, but not eradicate it altogether. As we discussed in class, statistical analysis of any data set reveals, quantitatively, how likely/unlikely an outcome is to occur. But just because an outcome is unlikely to occur, does not mean that it WILL not occur! So Nate Silver’s results may have been accurate – and that low-probability event occurred despite its data-driven unlikeliness.
The question that keeps lingering in my mind is: does the revelation of data analysis have any impact on human behavior? In this case – did all of the predictions that a Trump win would be highly unlikely actually cause people to go out and vote (or not go out and vote), and ultimately sway the results by driving a shift in behavior?
Really loved your post, Ellen, because I have been an avid Fivethirtyeight reader for a while on both sports and politics, and I definitely felt let down for many reasons after the 2016 election, not the most important but I definitely couldn’t help feeling a bit stupid for eating up everything on Fivethirtyeight without question after this massive miss. Though it doesn’t seem that another standout has emerged from this election cycle like Silver did in the 2008 election, which says to me everyone got this wrong.
The idea of opening up the data set I agree with a fantastic one, and even going further I think it could be a good business hedge against his media business by actually selling his data sets to be verified externally and even analyzed externally to check his analysis. This may bring on competitors, but it also may bolster his credibility. In the end, I would say this would be completely worth it.
Great post Ellen! I agree that Silver would benefit from trying to collect his own data since we now know that there are many issues with the other polling sources etc. However, I wonder if this is also a cautionary tale for how data analytics can have negative implications as well – especially when its wrong. For example – how many people didn’t vote because they believed the statistics and media that Trump was just a flash in the pan? I think this extends from politics to business as well – what is the danger of becoming overly reliant on our data models and do we have ways to intervene early if they’re leading us astray?