
Machine Learning in Caterpillar

Caterpillar is a leading industrial equipment manufacturer. In the new age of machine learning and artificial intelligence, how can they grasp the rise of new technology to grow their business and maintain their edge?
Caterpillar is one of the world’s largest heavy industrial equipment company. Being the leader in the field for half a century, the company is facing more competition from its competitor John Deere. In 2017, John Deere acquired machine learning firm blue river [1]. The trend in the industry is obvious, traditional heavy industry are also moving fast towards utilizing machine learning to improve performance of the equipment. How would Caterpillar response to this trend?
Machinery maintenance is always a big cost of operating the heavy machinery and if not properly maintained, the failure often leads to huge cost or worse, tragic outcome. Traditionally, product feedback or improvement happens in a much longer cycle, which involves user feedback or investigation after incidents happened. By utilising machine learning, this could be dramatically improved in the way that data can be collected in real time basics and failure could be predicted after enough data was collected and failure predciting models were establish. The other area that machine learning can help improve the performance is the human augmentation. By utilizing computer vision and machine learning, the system can warn the operator about potential hazard and other ground operators. But the problem to develop such algorithm is that to make such algorithm work, there needs to be a large amount of accurate labeled data. It took large amount of labor to tag the data and validate them.
It is important for caterpillar to develop the massive data collection and analytics capability for the above reasons. Caterpillar’s management aims to utilize the machine learning to improve the automation/maintenance of the machines as well as the data tagging process. Rather than looking outward, Caterpillar choose to look inward to grow their business. They had partnered with Matlab to develop an internal platform for aggregating data from different parties. [2] The data was then passed on to engineers developing the algorithms at the back end. The process was made efficient with the help of a lot of built in library made available by Matlab. Also the auto tagging function of Matlab helps reduce the amount of work that taggers need to do.

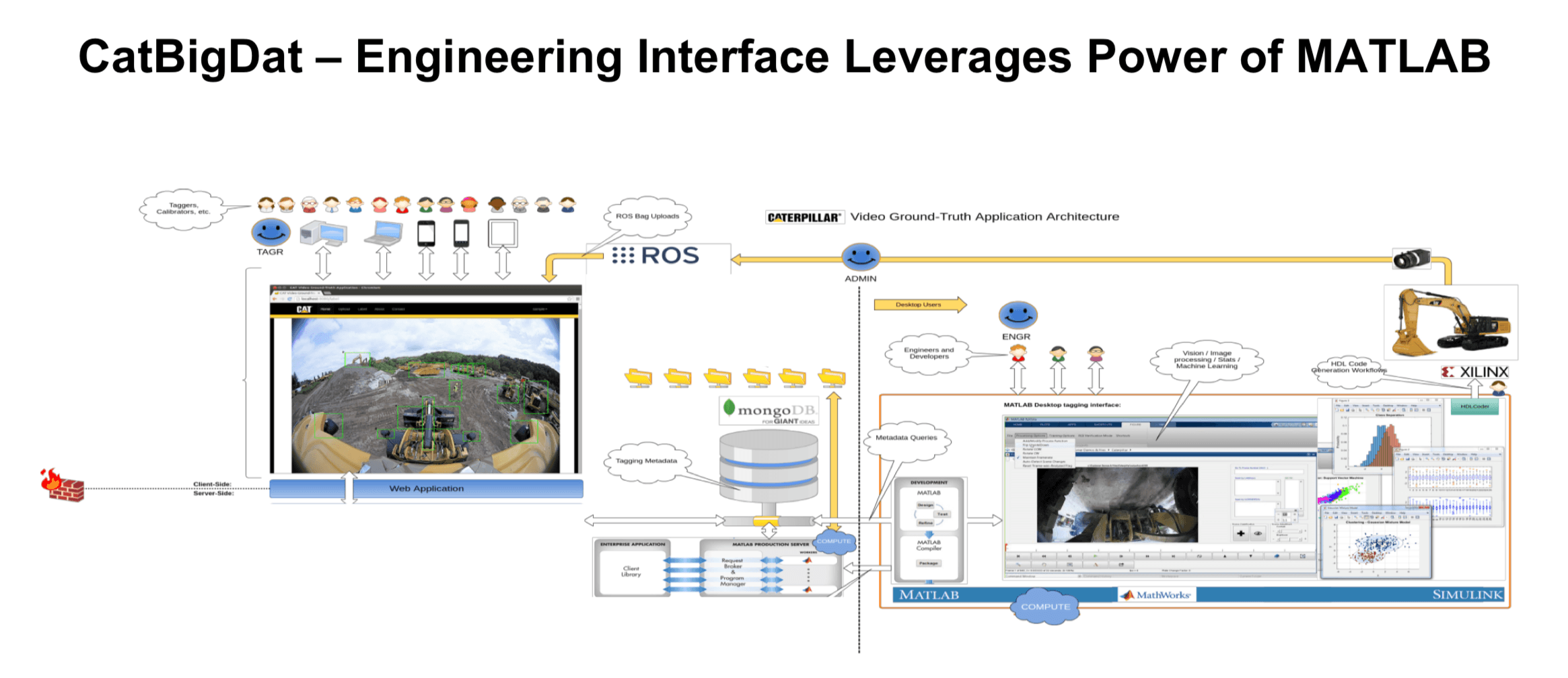
In the long run, the data analytics could be a standalone business itself offering as a subscription. This could be the next drive of their sales growth as the demand for machinery stagnate [4].
Besides the above-mentioned steps, I suggest Caterpillar to set up a centralized department inside the company to lead the data collection and learning effort. The efficiency of machine learning will be improved once the Following the same logic, the company should also dig deeper in the data to link it with fundamental science (metal fatigue failure etc.) to find out common patterns of failure mode so the same logic can be applied to other products lines. Another interesting approach is to form joint venture/spin out company to transfer knowledge to other heavy industry such as turbine/engine etc.
Moving ahead, there are two questions that matters to the implementation of machine learning in Caterpillar. First, what is the reliability of the product you need to get to before you release the product out to the market? All these heavy machineries are high stake in terms of work place safety, how reliable the algorithm should the company improve to until release to customer? Is the internal product development process adapted enough to check such compliance?
Second, with a long cycle of replacement for machinery, what are the key strategies to accelerate the big data and machine learning initiative to make it beneficial to most users? Are there after market kits to be developed so that customers can deploy them on their own machines? How would that solve the connectivity in the sites that the machine operates. These are challenges that the company needs to solve before the technology could be widely benefit to its customer.
Looking ahead, there are a lot of opportunities and challenge for Caterpillar Inc. in the machine learning age. (720 words)
[1]Golden, K. (2018). Deere Acquisition of Blue River Technology | John Deere US. [online] Deere.com. Available at: https://www.deere.com/en/our-company/news-and-announcements/news-releases/2017/corporate/2017sep06-blue-river-technology/ [Accessed 13 Nov. 2018].
[2]Mathworks.com. (2018). [online] Available at: https://www.mathworks.com/content/dam/mathworks/mathworks-dot-com/company/events/conferences/automotive-conference-michigan/2017/proceedings/big-data-data-analytics-machine-deep-learning-infrastructure-at-caterpillar.pdf [Accessed 14 Nov. 2018].
[3]Goldbloom, A. (2018). We’ve passed 1 million members. [online] No Free Hunch. Available at: http://blog.kaggle.com/2017/06/06/weve-passed-1-million-members/ [Accessed 14 Nov. 2018].
[4]Nash, K. (2018). Caterpillar Ramping Up Data Services Business. [online] WSJ. Available at: https://blogs.wsj.com/cio/2017/06/06/caterpillar-ramping-up-data-services-business/ [Accessed 14 Nov. 2018].
I found the concept of Caterpillar spinning off their data analytics capabilities as its own product to create a new revenue stream really compelling. You recommend that Caterpillar set up a centralized department inside the company to lead the data collection and learning effort. Is this is common practice in large organizations today, or would this approach be unique to Caterpillar? Is it possible for them to source related data that could be helpful (from the self-driving car industry perhaps)?
Great discussion! Its interesting to see how a company like Cat is looking to improve it’s processes using new tools like machine learning. I think your point on safety is a very pertinent one where machine learning could definitely play a role. I definitely see connectivity being a key issue (specially on remote work sites).
Interesting article. Given the trend of internet of things now, more data will be collected for better machine maintenance,
I think you’re consideration on how good do the machines have to be before we trust them is a very important one to consider. Elon Musk has a great commentary on this. Below is the link to the interview (minute 3:20) and he discusses that humans will not trust a self driving car if it is a 0.01% chance of getting into an accident. Humans would trust it if the car had a likelihood of a 1 in one hundred lifetimes or 1,000 lifetimes chance of getting into an accident. I am not sure if we would need this high of trust with machinery like Caterpillar machines given the nature of the job but nevertheless trust is an important concern.
https://www.youtube.com/watch?v=oQh3_c6OLRU
The role of machine learning in a high stakes environment is an interesting question. This past summer while traveling around Nepal I was surprised to learn that the first equipment a municipality buys with its budget is often a JCB or Caterpillar excavation machine. Often these municipalities run on a tight budget and are extremely far from the nearest service stations. Yet the excavators are extremely crucial especially during monsoon season when landslides are likely to occur. The ability to proactively detect the problem ahead of time and alert the owners would be truly useful in such geographies.
Interesting topic and a good article on it.
A couple of thoughts on the matter.
First, I’d be interested in how to set the tasks for ML that would actually relevant for the customer? True, safety issues are worth dealing with, but what if the customer actually tackles them in a very efficient way already without any ML algorithms? Additionally, CAT would also need to provide training packages for the clients not accustomed with new interfaces and ML implications.
I believe, another challenge for CAT would be to find a way to get all the data from client experience to enhance the database and train ML. Although clients would be likely willing to help the company to improve its performance, there still remains a threat that dissatisfied customer, who actually have the most interesting additions to the dataset, would be less willing to share info about failures. This is especially true for the remote areas without any internet connection so that sharing the data would incur additional cost to the customer.