
Image recognition at Facebook: How machine learning is helping computers — and people who are blind — ’see’ digital photos
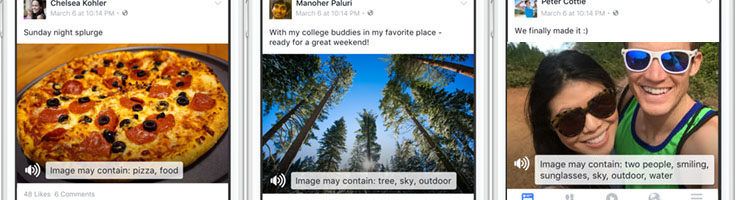
As we become increasingly reliant on machines to perform our daily tasks — from answering our emails to driving our cars — we are exposed to the limitations of technology as it attempts to perform complex human operations such as natural language processing and image recognition. To address this, Facebook is leveraging its repository of user-uploaded photos to improve accuracy of image recognition technologies to enable computers — and people who are blind — to ‘see’ in natural contexts.
Image recognition enables Facebook to deliver value to users and advertisers
Every day, Facebook users share more than two billion photos across Facebook’s suite of products (Facebook, Messenger, Instagram and WhatsApp)1 — making Facebook one of the largest and fastest growing repositories of images, and the largest photo sharing service in the world.2
While photos have been a major part of Facebook’s growth and success, they also present unique opportunities, challenges, and limitations for the company as it expands.
Photos provide Facebook with an uncontaminated glimpse into the behavior and preferences of Facebook’s 2.27 billion monthly active users (MAUs).3 By categorizing the photos that users upload and engage with (e.g. using Facebook’s reaction tool4), Facebook can better understand how users spend their time and the types of content they’re most likely to find interesting.
As Facebook grapples with its slowest revenue and user growth rates in history (see chart below)5, it is crucial that the company identifies new ways to deliver value. Robust image recognition technology will allow Facebook to collect more meaningful data about its users, which Facebook can then monetize by enabling its advertisers to target content more strategically.


Image recognition technology will also enable Facebook to deliver on its mission of “giving people the power to build community and bringing the world closer together.”6 Historically, fulfilling this mission has been especially challenging as Facebook attempted to reach users who are blind or have low vision (approximately 285 million people, globally7). By integrating image recognition technology with Facebook’s existing VoiceOver capabilities, individuals who are blind are able to experience the world of Facebook independently (without the help of friends or volunteers), thereby growing Facebook’s overall user base.8
Improving the accuracy of image recognition using ‘wild’ data
Traditionally, image recognition models have been trained on datasets of photos that have been manually annotated by humans.9 However, there are certain limitations to these models: relatively few of these databases exist because it is both labor- and computationally-intensive to build these datasets and to train machine learning models based on the data.10 One of the most commonly used image datasets, ImageNet, which has been used to train image recognition models at IBM11, Microsoft12, and Google13, only comprises approximately 14 million images.14 As Facebook endeavored to create image recognition technologies to extract and organize information from billions of user photos, a more robust solution was needed.
To address this challenge, researchers at Facebook experimented with training its image recognition network on public images uploaded through Instagram15 — a service Facebook acquired in 2012.16 Rather than manually annotating each picture, Facebook tested whether user-generated hashtags could approximate human-annotations for training purposes.17 By using a dataset comprised of 3.5 billion Instagram photos, Facebook was able to achieve an all time record-high score of 85.4 percent on image recognition accuracy — a two-percent increase over the previous record.18
The limitations and implications of ‘wild’ data
While this research revealed that it is possible to use organic or “wild” datasets to train image recognition networks, the accuracy and scalability of Facebook’s image recognition model is limited by the diversity and quality of the user-uploaded photos and the user-generated “hashtags.” To address this limitation, Facebook will need to crowdsource a more robust dataset of annotated images for training these models.
In line with Facebook’s broader business objectives, one way to build this dataset would be to attract and retain a more geographically, racially, socioeconomically diverse user base — but doing so takes time. In the interim, Facebook could partner with other global technology companies (e.g. WeChat) to crowdsource images, thereby improving the overall accuracy of image recognition algorithms.
Furthermore, as Facebook continues to explore leveraging user-generated content to improve its image recognition tools, they must carefully consider the privacy implications of this new model. Given the long-term nature of this initiative, it may be worthwhile to consider the strategic benefits of a formal partnership with academic institutions or policy groups to establish best practices for user-sourced image recognition models. In the absence of formal privacy regulations or frameworks, technology companies will be responsible for determining the appropriate applications of user content — ultimately posing the question: are users able and capable of identifying if (and when) these applications cross a line when it comes to privacy?
(797 words)
Sources
1 Facebook, “Using Artificial Intelligence to Help Blind People ‘See’ Facebook,” https://newsroom.fb.com/news/2016/04/using-artificial-intelligence-to-help-blind-people-see-facebook/, accessed November 11, 2018
2 Newton, Casey. “The big pictures.” The Verge, May 17, 2017. https://www.theverge.com/2017/5/17/15650096/google-photos-new-features-shared-libraries-printed-books-io-2017, accessed November 11, 2019
3 “Facebook Reports Third Quarter 2018 Results,” press release, October 30, 2018, https://investor.fb.com/investor-news/press-release-details/2018/Facebook-Reports-Third-Quarter-2018-Results/default.aspx, accessed November 12, 2018
4 Facebook, “Reactions Now Available Globally,” https://newsroom.fb.com/news/2016/02/reactions-now-available-globally/, accessed November 12, 2018
5 Business Insider Intelligence, “Facebook Q3 revenue and user growth decelerate, but the company will seek growth in Stories and video,” October 31, 2018, via Business Insider Intelligence, https://intelligence.businessinsider.com/post/facebook-q3-revenue-and-user-growth-decelerate-but-the-company-will-seek-growth-in-stories-and-video-2018-10, accessed November 12, 2018
6 Facebook, “Company Info,” https://newsroom.fb.com/company-info/, accessed November 11, 2018
7 World Health Organization. Global Data on Visual Impairments 2010. Accessed November 11, 2018
8 Facebook, “Under the hood: Building accessibility tools for the visually impaired on Facebook” https://code.fb.com/ios/under-the-hood-building-accessibility-tools-for-the-visually-impaired-on-facebook/, accessed November 11, 2018
9 Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: ImageNet Large Scale Visual Recognition Challenge. IJCV (2015)
10 Mahajan et al., “Exploring the Limits of Weakly Supervised Pretraining,” Facebook Working Paper, https://research.fb.com/wp-content/uploads/2018/05/exploring_the_limits_of_weakly_supervised_pretraining.pdf, accessed November 2018.
11 IBM, “IBM Research achieves record deep learning performance with new software technology,” https://www.ibm.com/blogs/research/2017/08/distributed-deep-learning/, accessed November 11, 2018
12 Microsoft, “Training Deep Neural Networks on ImageNet Using Microsoft R Server and Azure GPU VMs,” https://blogs.technet.microsoft.com/machinelearning/2016/11/15/imagenet-deep-neural-network-training-using-microsoft-r-server-and-azure-gpu-vms/, accessed November 12, 2018
13 Google, “AutoML for large scale image classification and object detection,” https://ai.googleblog.com/2017/11/automl-for-large-scale-image.html, accessed November 12, 2018
14 Image-Net, http://www.image-net.org, accessed November 12, 2018
15 Facebook Code, “Advancing state-of-the-art image recognition with deep learning on hashtags”, https://code.fb.com/ml-applications/advancing-state-of-the-art-image-recognition-with-deep-learning-on-hashtags/, accessed November 11, 2018
16 Facebook, “Facebook to acquire Instagram,” https://newsroom.fb.com/news/2012/04/facebook-to-acquire-instagram/, accessed November 12, 2018
17 Facebook Code, “Advancing state-of-the-art image recognition with deep learning on hashtags”, https://code.fb.com/ml-applications/advancing-state-of-the-art-image-recognition-with-deep-learning-on-hashtags/, accessed November 11, 2018
18 Mahajan et al., “Exploring the Limits of Weakly Supervised Pretraining,” Facebook Working Paper, https://research.fb.com/wp-content/uploads/2018/05/exploring_the_limits_of_weakly_supervised_pretraining.pdf, accessed November 2018.
Facebook currently suggests tagging individuals that it believes are in photos that are uploaded. When users do choose to tag those people, it provides a positive feedback loop to Facebook’s image recognition algorithm. It seems likely that Facebook might be able to use this same user feedback mechanism to reinforce its use of ‘wild data’.
Assuming Facebook is able to further refine its image recognition capabilities, what do you think the broader business applications are of this technology?
Sal Paradise: That’s definitely an interesting question. I could see it being used for automatic traffic tickets, finding criminal suspects, and tracking people anywhere and everywhere they go. There’s definitely some major privacy / human rights issues associated with this kind of tech, and it will be interesting to see how it gets regulated in the future.
Facebook’s use of wild data to train its image recognition models is an interesting and somewhat risky decision. User-generated hashtags often cover a range of topics that relate to the image content in an abstract sense, such as an emotion that the image evokes or something personal to the user. From my experience, it seems like people do not usually tag concrete objects or details within photos, and these would be more generalizeable and of interest for accessibility applications. I find it surprising that the accuracy of Facebook’s image recognition models improved with the use of wild data, but this is a promising opportunity for the company to access a larger pool of data.
The issue of user privacy is very sensitive, especially given Facebook’s recent and widely publicized scandals. Users will likely react strongly to any perceived breach in privacy, so Facebook will need to anticipate these challenges and talk to its audience early to control the message.