
AIR Worldwide: Machine Learning’s Role in Risk Modeling
AIR Worldwide is leading the way in utilizing predictive modeling to identify, assess, and mitigate catastrophic risks.
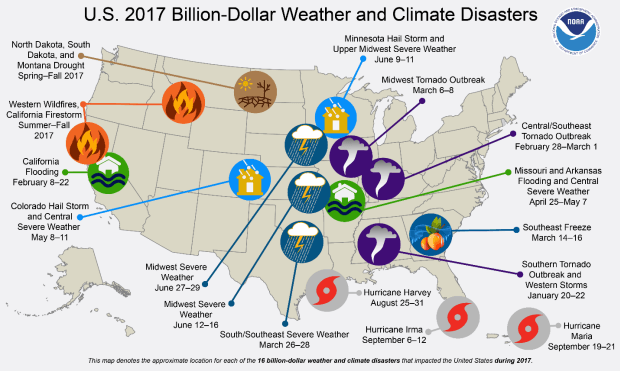
In 2017, Hurricane Harvey, Hurricane Irma, and Hurricane Maria caused financial losses of over $260B in the United States. In the same year, the Western Wildfires recorded losses of over $18B.[1] Cyber crimes are expected to cost approximately $6 trillion per year through 2021.[2] While the financial and emotional impact of catastrophic events can never be fully eliminated, utilizing machine learning to further improve the probabilistic modeling of future events can help individuals, governments and companies mitigate the impact of catastrophes before they occur. AIR Worlwide (“AIR”) has operated at the forefront of the risk modeling industry since 1987, helping companies and governments understand their risk from ‘infrequent but severe events” – both natural hazard and man-made – and better-equipping underwriters to create statistically sound financial assessments of what’s at stake.[3]
AIR’s value proposition is built on delivering the most accurate exposure to imperilment for clients facing a potentially wide range of natural and man-made risks. Machine learning has drastically improved the speed and accuracy of those assessments by “processing larger volumes of data” and “efficiently [tackling] the problem” in a way that enhances the quality of the answer delivered to the end client.[6]
Looking forward, further integrating machine learning across AIR’s product lines provides the opportunity to better “customer experience, improve risk-based pricing, real-time disaster response, fraud detection and much more.”[7] This evolution requires continued investment in quality data sources and training its models to respond to changing conditions (e.g. climate change). For some industries, data quality is a comparatively larger challenge that companies like AIR must address to retain credibility. For instance, when applying this risk assessment technique to flood, improving both the accuracy of topographical flood maps and the recency of data proves paramount. Over-reliance on the products without recognizing those limitations in the current data-set can cause dramatic under-estimations of potential risk similar to what occurred with Hurricane Harvey.[8] While machine learning may help AIR attain a better and more accurate prediction of risk, there is still room for human judgment and evaluation in assessing decisions around underwriting, insuring, and mitigating risk. As data quality improves, AIR has the opportunity to test-and-learn with different types of mitigating actions as the insurance and preparedness industry becomes better equipped to respond to varying levels of risk. AIR and its risk modeling competitors have the opportunity to meaningful drive behavioral change with regard to both natural (e.g. flood, earthquake, wildfire, etc.) and man-made hazards that could lessen the financial impact on society as a whole.

The development of highly accurate technology to best predict catastrophic events introduces several challenging ethical questions. First, how do AIR and its competitors balance the needs of three distinctly different types of customers – companies, organizations and governments seeking to utilize its data to assess, understand, and mitigate their risk; insurance companies trying to best price insurance and mitigation options; and reinsurance companies and the catastrophic bond market seeking to diversify risk and rewards across a portfolio of opportunities? Additionally, as the impact of climate change increases, some have called for open platforms where this information can be readily available for the average consumer. What responsibility comes with having the capability to predict and, therefore, mitigate the impact of catastrophic events? AIR and its competitors are private companies utilizing this information to make a profit. Is a world foreseeable where this type of information is viewed as a public good?
(745)
[1] National Climate Data Center, “Billion-Dollar Weather and Climate Disaster,” https://www.ncdc.noaa.gov/billions/events.pdf, accessed November 2018.
[2] Eubanks, Nick, “The True Cost of Cybercrime for Business,” Forbes, July 13, 2017. https://www.forbes.com/sites/theyec/2017/07/13/the-true-cost-of-cybercrime-for-businesses/#153d9ca94947, accessed November 2018.
[3] AIR Worldwide, “Our Story,” https://www.air-worldwide.com/About-AIR/Our-Story/, accessed Novembr 2018.
[4] AIR Worldwide, “Our Story,” https://www.air-worldwide.com/About-AIR/Our-Story/, accessed Novembr 2018.
[5] “AIR Worldwide Develops Probabilistic Model for Global Cyber Risks,”, Insurance Journal, October 22, 2018, https://www.insurancejournal.com/news/national/2018/10/22/505209.htm, accessed November 2018.
[6] Bentley, Adrian and Rob Savitsky, “How AI and Machijne Learning Are Disrupting Reinsurance Optimization,” Global Reinsurance, June 27, 2018, https://www.globalreinsurance.com/news/how-ai-and-machine-learning-are-disrupting-reinsurance-portfolio-optimisation/1427523.article, accessed November 2018.
[7] Chuney, Bill, “Embracing the Future of Catastrope Modeling,” December 14, 2017, https://www.air-worldwide.com/Blog/Embracing-the-Future-of-Catastrophe-Modeling/, accessed November 2018.
[8] Blosfield, Elizabeth, “Insurance Industry is Rethinking Cat Modeling After Last Year’s Disasters,” Insurance Journal, July 16, 2018. https://www.insurancejournal.com/news/national/2018/07/16/495213.htm, accessed November 2018.
Jane D., awesome read. It’s interesting to think about this kind of information as a public good! Honestly, as I was reading your submission, the first thought that came to mind was parallels with the movie “The Imitation Game” and their use of computers to decipher “The Enigma” code system during World War II: https://en.wikipedia.org/wiki/The_Imitation_Game
There are definitely ethical concerns with associated with knowing a catastrophe will likely occur and what you do with that information especially when human livelihood is on the line. At the same time, without the appropriate monetary incentives, does continued innovation in this area go away?
This is a really tough question for organizations like AIR but I think that bringing this discussion front and center is necessary in the evolution of advances such as these.