
When Confirmation Endangers Analytics

At HBS, we are trained to make effective decisions based on incomplete data, and after two years of reading hundreds of cases, a lot of us become really good at advising CEOs about what they should do to solve a complex dilemma by glancing at a few exhibits and doing some quick maths. However ironical it may sound, it IS a valuable skillset to have and there is no denying that being able to solve a problem quickly is required in today’s business world.
But here’s the catch. Humans are imperfect. Especially when the times come to make important decisions. We are all subject to biases and we tend to believe that the more data we analyze, the more lines of code we write, and the more visualization we create, the less vulnerable we will be to these biases. This is unfortunately not true.
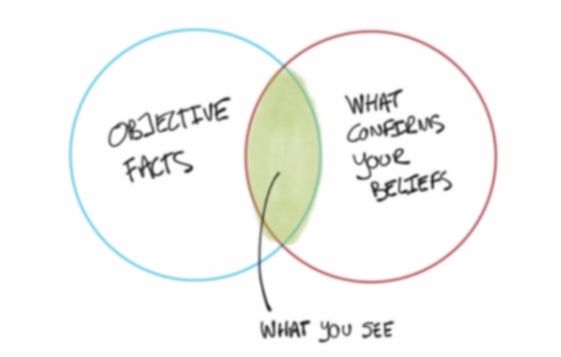
I came across this interesting article by Jonathan Davis that tries to prove that data analysis – even in the early phases of exploration – can lead to erroneous conclusions because of one of the most common cognitive shortcuts we all have: confirmation bias. I generally agree with his position and I can try to illustrate this opinion by a couple of examples I have seen in the business world, but also in our very own LPA class.
In class, every time we worked on a Deepnote notebook we had one clear ultimate goal: try to come up with a model that explains as objectively as possible which variables lead to a certain outcome: Does the fact that a mountain guide is from France improves the odds of his team making it to the top of Mount Everest? If you’re like Sarah Powers, you might wonder if the number of emails you send each day influences whether or not you reach your sales quotas.
Interestingly, we do not always spend time trying to understand the dataset we are working with: Why did we select these specific variables? Is it because we already assume that at least one of them is going to answer our question? How has the data been collected? Why do we automatically see some variables as ‘dependent’ and others as explanatory (or independent)? We usually have a hypothesis before looking at a dataset. And this is a good thing. But how we phrase our hypothesis has a direct consequence on how biased our final conclusions can be. “Strong networks lead to better sales performance” and “Sales quota attainment is largely explained by the number of emails sent” are not the same hypotheses. That causes us to potentially look for different sets of variables and test slightly different models. Additionally, as we saw multiple times in class, the causality link is assumed, but can’t be proven by historical data. What if a great salesperson feels compelled to help their peers by sharing best practices, thus sending more emails as a result? The truth is that we are not ‘incentivized’ to look too much into these questions partly because of confirmation bias.

I am not saying we should have because that was not the purpose of the class, but this leads me to question how this type of analysis is usually done ‘in the real world’. Business environments are far from being ideal data laboratories. Is the analysis being made in order to support a decision that senior leaders already plan to make? I have encountered numerous situations where the next course of action had – even implicitly – been selected but managers needed more data to build a compelling business case to justify it. I have heard so many times “Stéphane, I need a data point that shows…”. Is that the way we are supposed to start a data analysis? Let’s imagine another scenario: a salesperson does not reach their sales quotas and is being asked for a justification. It is extremely tempting for them to find in all the available data some proof that the cause is linked to an event out of their control.
I feel that, even if confirmation bias can not be completely eliminated, we have to make every effort to reduce it. This is especially true in people analytics for obvious moral reasons. When you are analyzing issues that are linked to people, you usually do so to make decisions around hiring, promotions, productivity, well-being, or firing. Relying on biased data or analyses for these purposes seems alarmingly wrong.
So next time we schedule a meeting with our managers to present the conclusions of our complex analysis, why don’t we ask ourselves: Is it as easy to find data that supports the opposite view?
Article:
Jonathan Davis, Confirmation Bias Is The Enemy Of Exploratory Data Analysis,
https://towardsdatascience.com/confirmation-bias-is-the-enemy-of-exploratory-data-analysis-c6eaea983958
Thanks for sharing your thoughts, Stéphane! I could relate to your story of managers asking for any data point that supports their hypothesis and I definitely want to be asking myself more frequently how easy it would be to find data that supports the opposite side. In the end, it takes humility to admit that our hypothesis (and the beautiful narrative crafted around it) could be wrong. As soon-to-be-managers, it’s exciting that we will have more power to ask the team to take a step back and consider whether our approach to data analysis is biased.
Thanks for your comment! I agree that being aware of potential biases in analyses can definitely make us better managers, and ultimately more confident in the conclusions we reach.
Loved your reflection Stephane, very clear and insightful as usual. Is it possible that having and analyzing data can give us a wrong sense of understanding? can we really understand people and their behaviors by looking at numbers? the r-squared would tell you so, but especially in people analytics, we need to be especially aware of what we are looking for and testing, as you mentioned.
Very interesting point! Makes me wonder what part of the analyses that we do in business contexts is actually done to reassure ourselves that the problem we face can be broken down into a set of variables (ie. giving the illusion that we ‘understand it’) versus the ones that intend to thoroughly look at data and reach the best possible conclusion.