
Locked in by Algorithms?

In courts around the country, risk-assessment algorithms determine who gets bail and who has to stay locked up. Can we avoid perpetuating the systemic biases of the justice system with these automated tools?
Bail and risk-assessing algorithms
The US justice system uses bail to impose restrictions on an individual before trial. The purpose of bail is three-fold: (i) to ensure that the defendant will show up to court, (ii) to allow the defendant to proceed with their life until a firm sentence is made, (iii) to lower the incarceration rate, reducing prison system costs.
If bail is not set correctly, we face two possible negative outcomes:
- If too low: bail fails to achieve (i), since the defendant may lack the incentive to show up to court
- If too high: the defendant cannot pay, and bail fails to achieve (ii) and (iii)
Traditionally, it is up to the judge’s discretion to set the bail. There are two main reasons why this has proven problematic. First, it can be very arbitrary (e.g. some judges in New York City are more than twice as likely as others to demand bail [1]). Second, judges are humans and as such are not exempt from unconscious biases.
To combat these shortcomings, more and more states have introduced risk-assessing algorithms. These algorithms offer a risk score of the defendant that accounts for the probability of a no-show to court and/or recidivism. The score is provided to the judge to inform the bail decision, but not to mandate it.

The results are in: automated risk assessment and inequity
Many hope that the introduction of algorithms in the bail process will result in a more efficient and fairer system, but evidence is mounting that points to the contrary.
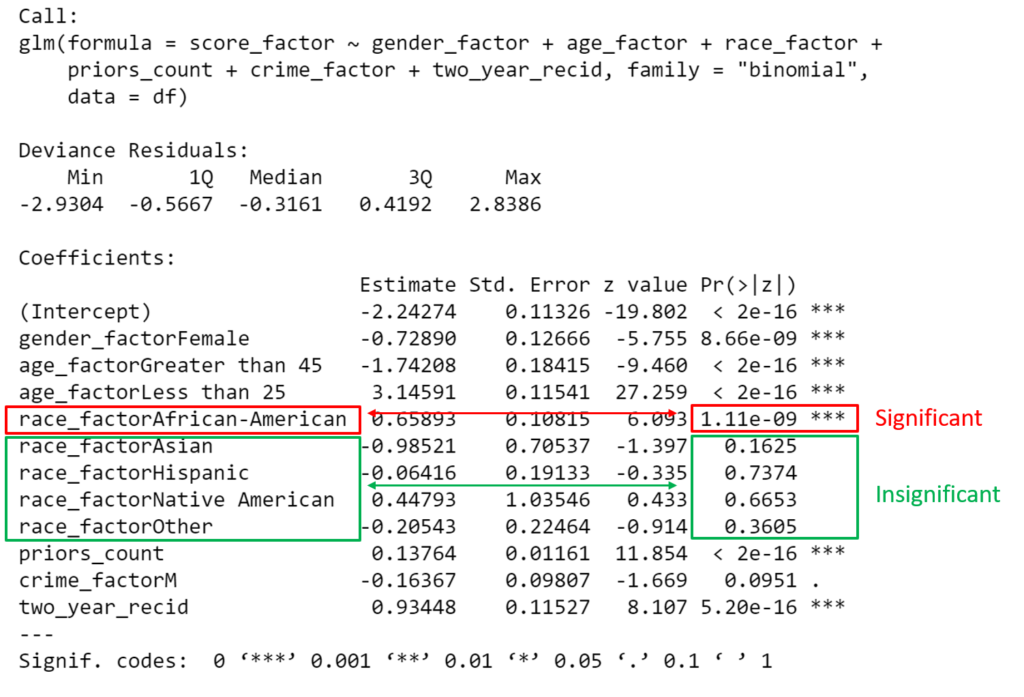
Algorithms do not eliminate bias, but in fact can perpetuate inequities found in the historical record. A 2016 report by ProPublica on Broward County, Florida looked at risk scores generated by algorithms, and discovered that the scores rated black defendants significantly more likely than white defendants to be a risk of committing a violent crime [2].
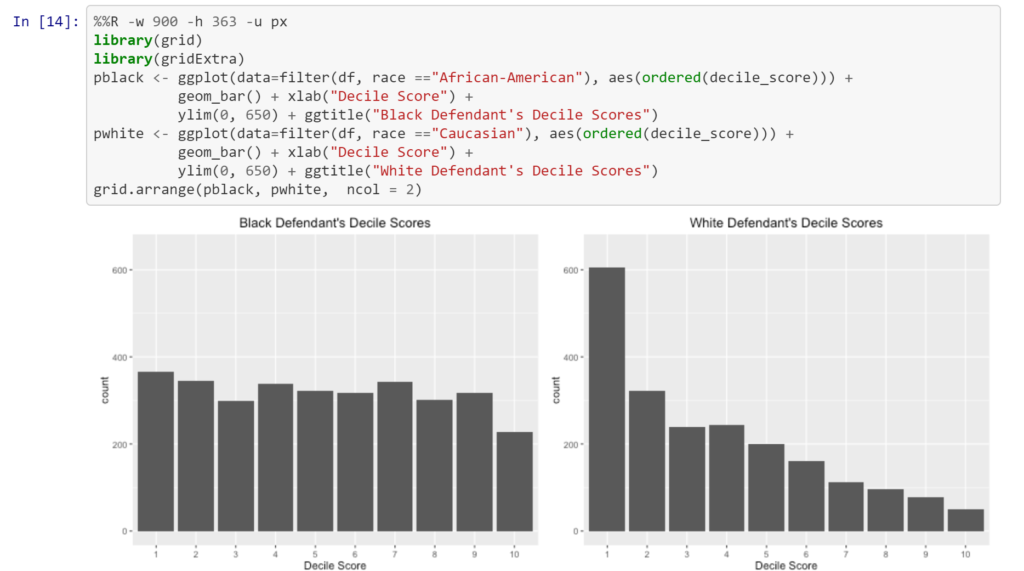
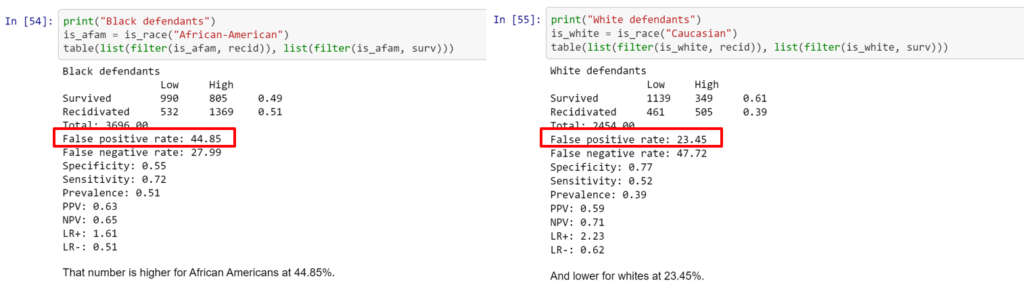
In his Wired article [3], Tom Simonite uses evidence from the state of Kentucky to unveil similar consequences of use of risk-assessing algorithms. After passing a law in 2011 that requires that judges consult the risk score, the state saw an overall increase in the proportion of defendants granted release, but that increase was significantly larger for white defendants than it was for black defendants.
In defense of the algorithm
So are we stuck? Should this evidence of inequitable outcomes doom predictive risk-assessment models? While experts agree that bias is a major concern, some try to find a middle ground.
Simonite’s tone in this article is very critical towards algorithms in this context, his criticism suggests that there might still be hope to use predictive modeling (though I’m not sure he would agree with that assessment). He highlights that what often prompts the judge to make biased decisions is not the result of the algorithm but the judge’s interpretation of it. A Kentucky study [4] showed that, given a moderate risk score, judges were more likely to release white people than black people.
In a 2017 New York Times article [5], González-Bailón and others point to benefits of algorithms in the bail context: incarcerated population decreases without an increase in crime. Evidence from Virginia, New Jersey and Philadelphia backs up their claim. They also dispute the notion that “algorithms simply amplify the biases of those who develop them and the biases buried deep in the data on which they are built”. Algorithms are not to blame for biases that are deeply engrained in the system. A well designed algorithm will not perpetuate such biases.
Concluding thoughts
One certainty is that relying only on judge discretion itself can result in bad outcomes. Judges, as humans, bring their own unconscious biases to decision-making and the inefficiency means more people in jail.
There are pros and cons to relying on algorithms. On the plus side they can:
- help mitigate biases from judge interpretation
- reduce incarceration rates
- make for a more efficient system in which judges can focus on ruling.
On the flip side, leaning on algorithms can:
- diffuse accountability
- perpetuate the racial discrimination inherent in the justice system if not well designed (as frequently appears to be the case today).
To me, the best outcome has to be an integrated human-machine decision-making process. We need to capture these benefits of automated risk-assessment while understanding and mitigating the bias they can bake into the outcomes.
Recognizing the complex results so far, I still support algorithmic risk assessment, but with clear checks and balances provided not only by the judge but also by an external auditing party.
References
[2] https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
[3] https://www.wired.com/story/algorithms-shouldve-made-courts-more-fair-what-went-wrong/
[4] http://www.law.harvard.edu/programs/olin_center/fellows_papers/pdf/Albright_85.pdf
[5] https://www.nytimes.com/2017/12/20/upshot/algorithms-bail-criminal-justice-system.html
[6] https://github.com/propublica/compas-analysis/blob/master/Compas%20Analysis.ipynb
Note: [3] is the article that prompted this post, the rest are references.
Very interesting article Paula. I kept going back and forth while reading it, tough to deice which side I fall on.
On one hand, i see the benefits of using algorithms to make the system more fair and equitable. However, the reliance on historical data is indeed a big drawback. While not an expert myself, the historical unfairness of the american judicial system, in particular on issues of race, have been hotly discussed lately. There are multiple articles, documentaries and movies on the topic. The data in this article even supports it. Therefore, the reliance on historical data to develop trends carries significant drawbacks that we don’t want to perpetuate.
Additionally, the point about education is incredibly important. Introducing analytics to the judicial system, an old and slightly archaic branch of government usually denominated by older professionals, will have a hard time finding strong footing. but this does not only apply to judges. it extends to the general public, majority of whom have to serve jury duty in case the claim goes to court.
Explaining to all these stakeholders what the code does and how to and not-to interpret will not be easy.
Considering all the above, I dont think they system is ready for such a change, at least not in the format and structure it is currently being offered.
Thank you for a very interesting read Paula, I had no idea that many states in the US judicial system are using algorithms to asses risk and set bail. In general terms, I’m all for the use of algorithms in this regard. even though the drawbacks are pretty clear (as in almost all use cases for algorithms we’ve seen so far in class), I do believe that the human-machine combo ends up delivering a better outcome than the old, human-only system. Yes, historical data fed into the algorithm will carry risk of bias, but at least we minimize the human bias by arming the judge with an “objective” tool that can guide their decision and avoid “anomalies” in setting bail. Perhaps a way to enhance the outcome of the algorithms would be to adjust the bail outcomes for the parts of the population that have historically seen negative bias.
Thank you for laying out all sides of this issue, Paula.
On top of the fact that the Compas model was trained on data that is likely rife with historical bias, I also believe that a huge issue with this model is that it was deployed in a context in which there is no ground truth against which to validate it. The model is trying to predict recidivism, but there is no metric of recidivism for those who are detained. Therefore, how can we ever know the true relationship between the characteristics/traits of a person and their rate of recidivism? I find it very difficult to trust an algorithm that cannot truly be validated against any metric or ground truth.
Thanks for writing about this topic! I find the idea of implementing a black box algorithm for this purpose to be quite concerning. Every crime and person involved comes with context. Stripping the holistic picture down to a few data points diminishes the purpose of having a criminal justice system that is (ideally) meant to assess this.
Very interesting post, Paula! There’s an economics professor from the University of Chicago, Jens Ludwig, who studies this very topic. He recently gave a guest lecture in one of my classes and he discussed how biases can be baked into algorithms. However, despite their potential to replicate the same biases as humans, he’s still a proponent of using algorithms because they are more transparent than human decisions and thus, can help us to reduce discrimination. Here’s a link to an article about it if you’re interested: https://review.chicagobooth.edu/economics/2019/article/how-making-algorithms-transparent-can-promote-equity
Considering this perspective, I definitely support algorithmic assessment along with you! I think it’s better than relying solely on human decisions, which we don’t have much insight into. By using algorithms, we can at least understand how decisions are made and adjust for systematic biases baked into them, while we also work to develop better algorithms that don’t exhibit bias to begin with.
Thank you for sharing that article, Aurora! It’s so eloquently written and I think it captures my sentiments after writing this post. This notion of transparency he talks about I think it’s the critical aspect here, and it’s what I had in mind when I wrote about the need for checks and balances and some kind of auditing body at the very end of the post.
Thanks again!
In addition to the benefits you outline, Paula, there are a few key advantages to an algorithm-based system that tip the scales for me. Most notably, algorithms help reduce intra- and inter-judge inconsistency on sentencing determinations. A 1999 research paper found that inter-judge disparity on average sentence length was about 17 percent (or 4.9 months) [1] and the statistics on intra-personal inconsistencies (whether you have a meeting before or after lunch) are similarly troubling. The only scalable way in my mind to ensure consistency is sentencing is through algorithms. While you may be able to help individual judges or specific counties become more consistent in their rulings, an algorithm is more reliable for system-wide change.
However, I absolutely agree that it’s key that any algorithm implemented needs to help correct for the biases that are deeply engrained in our judicial system. While I’m optimistic that such a solution is possible, with, as you argue, the appropriate checks and balances in place.
[1] http://users.nber.org/~kling/interjudge.pdf
Thanks for the interesting post, Paula. As a reformed former law student, it’s cool to see the beginnings of some cross-pollination between the data analytics space and the notoriously conservative legal world.
Generally, I’m an optimist for the use of algorithms in legal decisions as a means of structuring and standardising what was previously a highly subjective process. As you point out though, there are risks. Similar to Aurora’s comment above, I worry about transparency, but I worry just as much about legitimacy. Law students are taught that it’s not enough for justice to be done, justice must be seen to be done. We need the public to have confidence in the system, and for that to be true, they need to understand how it works.
Algorithms can help with transparency and auditability, but their potential for understandability is mixed. Legal decisions are not simple, they must reflect the complexities of the human experience and our desire to balance a host of competing objectives such as punishment, deterrance, rehabilitation, and protection. Every variable added to an algorithm makes it more complex, and even if it remains transparent and it’s possible for someone trained in data science to interrogate how a decision was reached, it may quickly become “too much” for a regular observer to understand.
We must balance our desires to achieve a more perfect algorithmic result against the need for the public to understand what is going on. If we fail to do so, we risk replacing judges sitting atop their ivory tower with algorithms buried inside an ivory box.