
Uber knows you: how data optimizes our rides

While Uber transports people and meals around the world without owning a car, they still rely on fuel: Data, data and more data – the magic word for Uber.
Everyone knows Uber. But dude, they know you at least equally well!
While Uber transports people around the world without owning a car, there is only one fuel that powers Uber: Data. This is the secret key driving growth of the silicon valley start-up revolutionizing the taxi industry. What makes Uber unique is that the data driven insights don’t just stay within its internal dashboards but are implemented real-time into its services to generate an unprecedented user experience for both customers and drivers.1
Wait, what’s the use of knowing my way to work?
Come on, you can do better! Uber uses data in many different ways with two applications standing out.
Matching Algorithms

Starting as soon as you open the app, until you reach your destination, Uber’s routing engine and matching algorithms are working hard. By entering the planned route and time of day, prediction models directly forecast the driving time and allocates the optimal driver through a process called batch-matching.
Through a machine learning algorithm, the models become more accurate in their predictive power with each ride filed. This matching algorithm allows Uber to minimize the number of variables a customer has to enter. In addition to that, they offer lower wait times and a more reliable experience for riders. Drivers, in turn, get more time to earn. 1
Surge Pricing
The instant implementation of live data allows Uber to effectively operate a dynamic pricing model. Using geo-location coordinates from drivers, street traffic and ride demand data, the so called Geosurge-algorithm compares theoretical ideals with what is actually implemented in the real world to make alterations based on the time of the journey. Using this process, fares are updated in real time based on demand. In addition, this allows prices to be adjusted specifically to different areas in cites, so that some neighborhoods may have surge pricing while others do not. 2
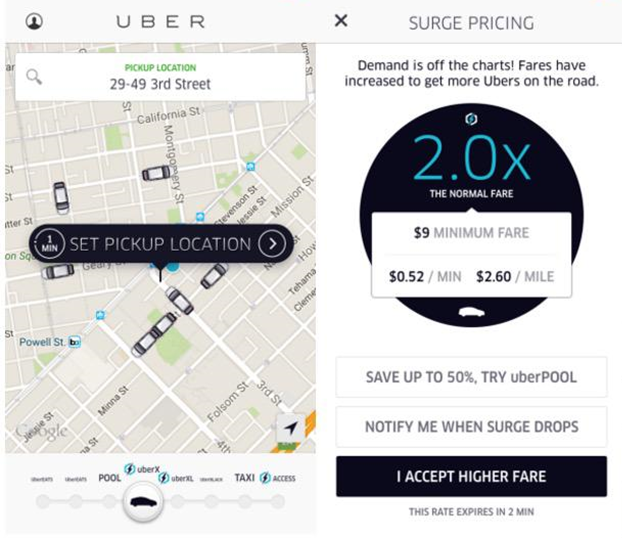
Furthermore, smart machine learning algorithms will take multiple data inputs and predict where the highest demand is going to be. During peak time, drivers receive live data in form of heat maps to compare the demand in different areas.3
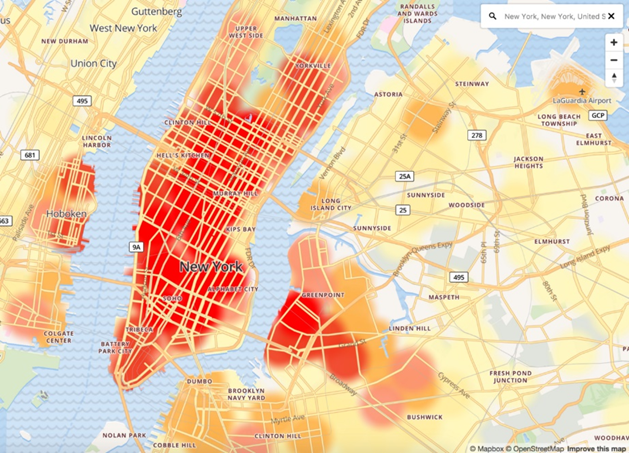
This system allows Uber to optimally position drivers ensuring that there is no supply and demand shortage. Doing so, they create the most efficient market and maximize the number of rides it can provide which in turn benefits all parties.1
But that’s billions of data – how do they manage?
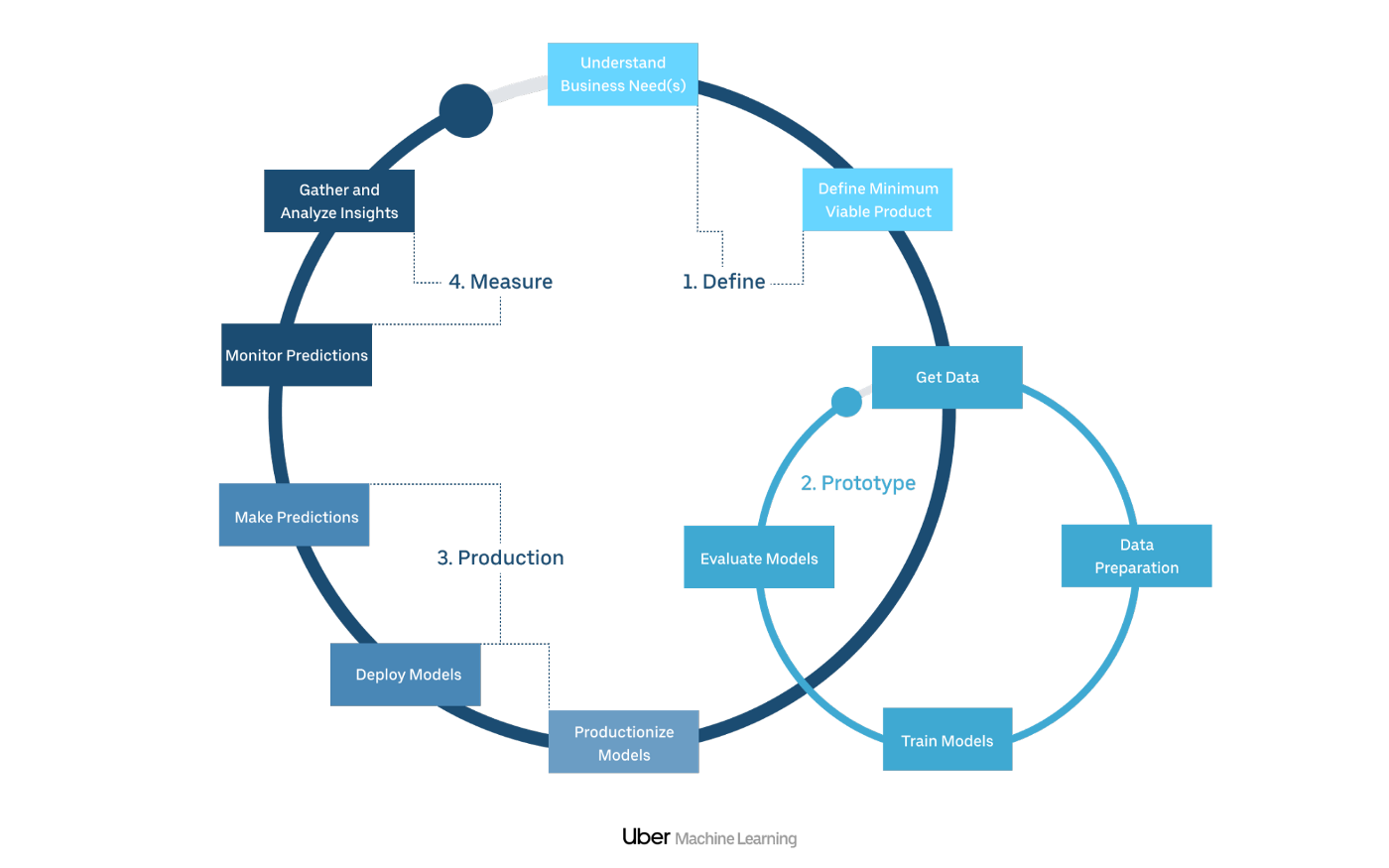
That’s right, Uber gives about 15 million rides per day.4 To manage this data flood, they introduced its own Machine Learning platform called Michelangelo which is used to create different models for Uber’s various services.
Michelangelo is an internal ML-as-a-service platform that democratizes and optimizes the scaling of AI, ML and Deep Learning. It enables internal teams to seamlessly build, deploy, and operate machine learning solutions at Uber’s scale. It is designed to cover the end-to-end ML workflow: manage data, train, evaluate, and deploy models, make predictions, and monitor predictions. For the Geeks, visit this page where Michelangelo is presented in detail.5
Boy, this sounds expensive – was it really necessary?
Hell yes! Before Michelangelo was born, Uber’s ML operations faced big challenges such as bad data quality, high data latency, lack of efficiency and scalability, and poor reliability. With its business growing exponentially, the amount of incoming data increased every day.
Being Uber means being efficient!
Travis Kalanick – Co-founder of Uber
To realize Michelangelo, new data scientists, analysts and engineers had to be hired and the computing power and its internet bandwidth had to be heavily increased.6,7 There are no exact spending figures available on this, but Ubers financials’ show that R&D spending increased by over 150 million8 over the year prior to implementation in 2017. Although the entire amount was certainly not invested in this project, we expect that quite some money was spent for Uber’s new best buddy.
So, all their problems are solved now?
You have no idea! Even though Uber has managed to successfully process and use the vast amounts of data, they still face major challenges. The most important to mention here are the status of its drivers, tax issues, constitutional issues and of course the rising competition of companies such as Lyft, Didi or Grab (details about challenges).9 In my view, however, Uber remains a highly competitive company with virtually no limits. Consider the diverse offerings such as packaging and food delivery, the upcoming driverless technologies and of course even air taxis which is by the way my favorite idea!
But Jesus! Think about how much data you need to manage for that!
Sources:
1 How Uber uses data science to reinvent transportation? (projectpro.io)
2 How Surge Pricing Works | Drive with Uber | Uber
3 When and where are the most riders? | Driving & Delivering – Uber Help
4 Scaling Machine Learning at Uber with Michelangelo | Uber Blog
5 Data Science at Uber. Uber is one of the most successful… | by Jagandeep Singh | Medium
6 Uber’s Big Data Platform: 100+ Petabytes with Minute Latency | Uber Blog
7 Evolving Michelangelo Model Representation for Flexibility at Scale | Uber Blog
8 Uber R&D spending worldwide 2018 | Statista
9 4 Challenges Uber Will Face in the Next Years (investopedia.com)
{kind=link}
Yannik — thanks for the post, it was both hilariously written AND interesting. It was thought-provoking to read about how Uber is able to adjust its services in real-time, versus using big data as an input to make its product better in the long-term. Even though Uber and Lyft have achieved mass scale, I do wonder if they will continue to be competitive with rising prices and the increased ubiquity of big data as a business asset.
Great post!
Something I have always thought of is if and how algorithms can be trained to show empathy and act ethically. Your point about Uber being able to selectively surge charge brings back memories of Uber surcharging during mass shootings. I wonder if at some point algorithms will be able to cross reference what is going on in the public domain (news, online, etc) with location info and at some point make these ethical decisions without human intervention.
Great blog and an interesting read Yannik! Uber has definitely done a great job in eliminating the customer pain points around commuting by leveraging customer data But as I see their increasing challenges especially in the developing economies like India: frequent cancellation by drivers, drivers insisting on cash payment due to lack of payment transparency for drivers (which was sorted 2 months back by uber after being in India for almost 10 years), poor customer service, and now rising competition with electric vehicle ride hailing player. Uber had been able to do good in the US and some part of the European market, but it has struggled from the beginning in the developing market due to stiff competition. I’m really curious to know what will be their next growth strategy, what will be their future? And how are they going to use the plethora of customer data to make their next bet?
Yannik, this was an awesome read! I used Uber/Lyft on a daily basis when I worked in consulting and am still a frequent user of it now so I love asking the drivers about how the app works for them. One of the fascinating things I heard was that if a top-rated driver is on their way to pick up a non-top-rated user and a top-rated user subsequently requests a ride, the app will cancel the original ride to the non-top-rated user and redirect the driver to the top-rated user instead. I understood this as the app ensuring that their top-rated users have the best service from their best drivers (not necessarily to incentivize users to be better riders, since most users are unaware of this mechanism) but reading from your post, it strikes me that it may also be a cost saving mechanism to link its best drivers and users to “minimize the number of variables” for both parties and curate highly efficient rides to increase capacity.