Text to Image AI – what the future holds?

Text to Image AI tool
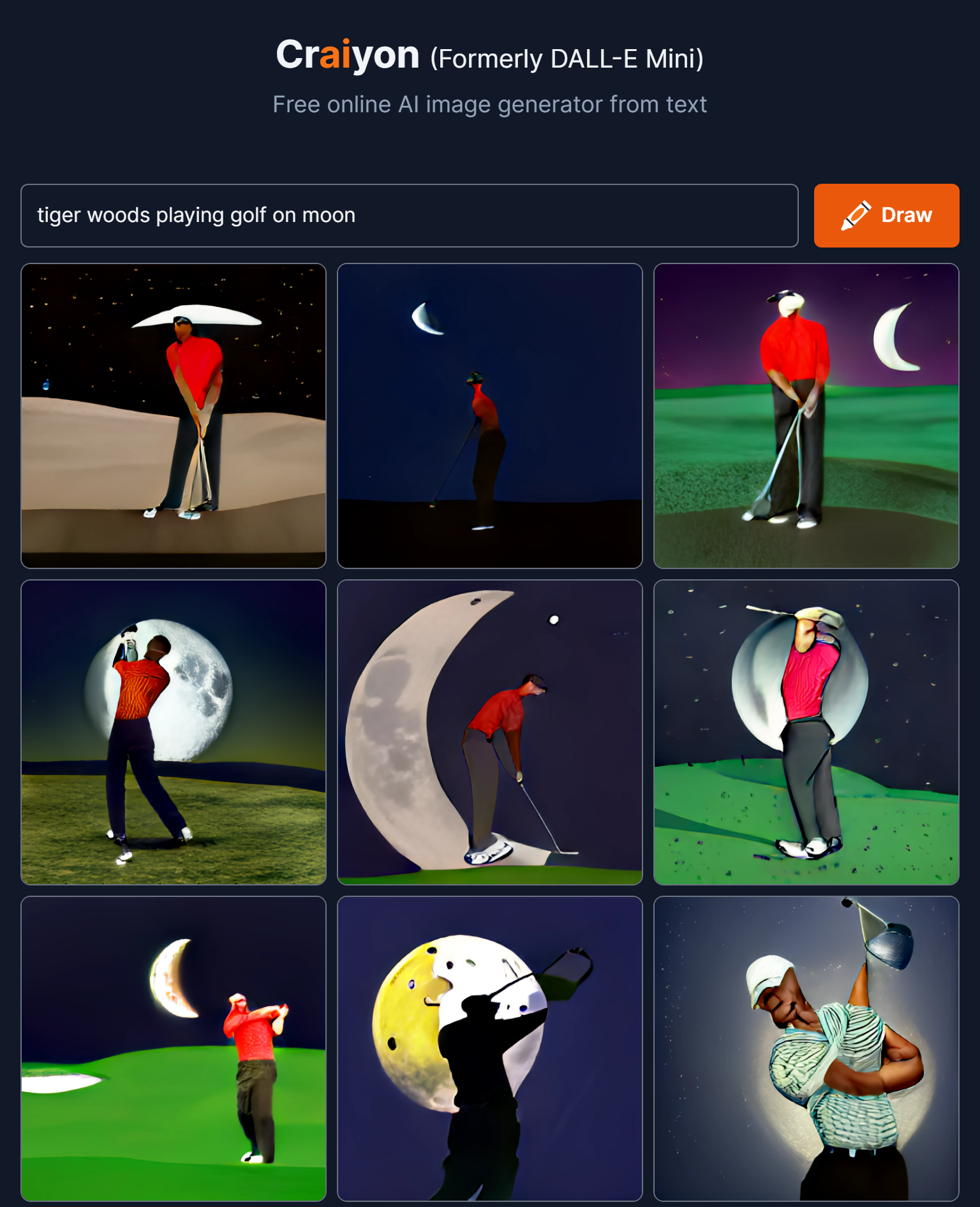
Craiyon is one fascinating tool for text to image generator using AI. As per my understanding it is based on an AI model that extracts connections between words and generates images by drawing on statistical patterns it gathered from analyzing labeled images.

But the image construction from the prompt is sometime little and sometimes a lot different from your expectation, one has to keep in mind the alternate meanings of the desired result. There are clearly some limitations of this tool like it doesn’t work well if you use different styles in one phrase like “photo” & “sketch” and same happens when the text prompts for the object or character to do something or involve in activity, the tool is slightly less successful. Additionally, the face images are distorted, like in the below image Tiger Woods face is distorted, which is the current limitation of this image encoder.
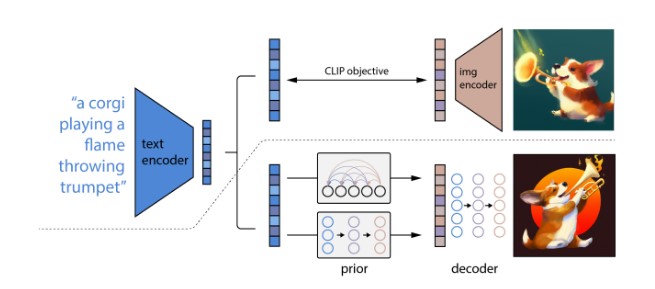
It is generally good at understanding the overall meaning and tries its best to provide the image as close as possible to the prompt, also the model has the potential to generate harmful stereotypes and exhibit biases because as per my understanding the model might be trained with some unfiltered data from internet. Therefore, still needs a lot of improvement to create better images from text. I’m concerned about two things 1) the impact on the jobs of the creative designers with the improvement in these tools, and 2)ethical issues due to the inherent bias in these tools. But overall, as AI becomes better with every iteration, it holds massive opportunities like text to video etc. for our future digital lives.