
TensorFlow and Open Sourced Machine Intelligence – Game Changer?

Google has just open-sourced TensorFlow, a machine intelligence engine that could rapidly accelerate startup opportunities in machine learning and AI.
In early November 2015, Google open sourced its in-house machine intelligence library named TensorFlow – a move considered potentially revolutionary by many in the industry. The TensorFlow toolset is used within several of Google’s core products, starting originally with Google Brain (an AI component of the search algorithm) and now including projects such as Photo Search, Voice Recognition, and Translate.
TensorFlow followed Google’s AI system DistBelief, which was created in 2011 and helped their team win a global machine vision competition with remarkable accuracy recognizing objects in images. TensorFlow has apparently been built with an open architecture in mind, unlike previous internal Google libraries. This means that the libraries can operate in a more standalone capacity outside of Google’s infrastructure. TensorFlow has improved on DistBelief’s neural network foundations substantially, enabling broad applications across different systems and dramatically improving the capacity for deep learning.
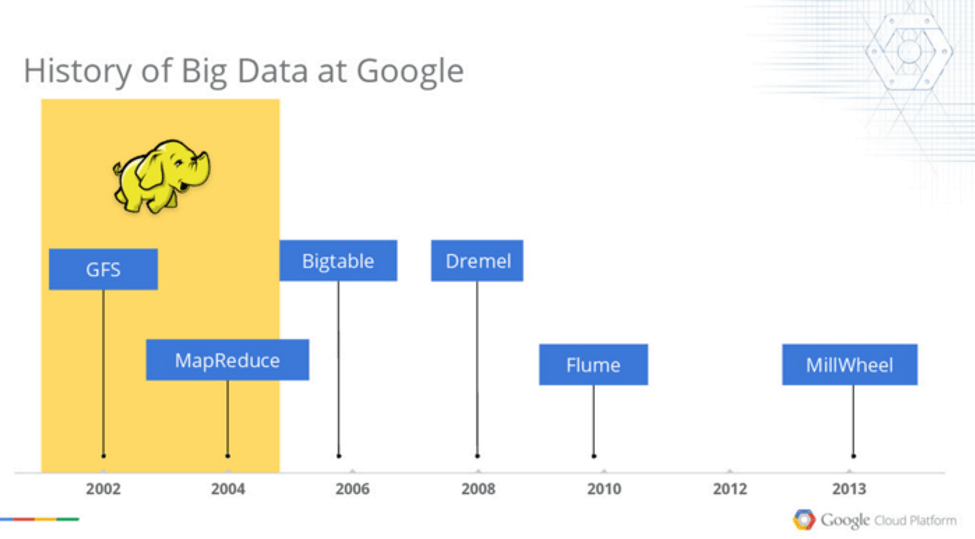
So why is this a big deal? Google, of course, has an incredible reputation for designing platforms that enable the large scale processing of data. Between 2002-2004, Google published papers explaining its proprietary Google File System and MapReduce technologies. This helped to establish a whole new generation of Big Data companies, such as Cloudera and Hortonworks, focused on developing Hadoop and MapReduce into commercial enterprises.
A partial history of internal data projects at Google is replicated below from an online presentation introducing the Cloud Dataflow project. Each of these projects has been at the bleeding edge of data processing, machine learning, and artificial intelligence as compared to the rest of the industry. The open-sourcing of TensorFlow represents a shift in Google’s strategy away from purely internal, highly customized toolsets. This has come at a substantial up front cost to Google in terms of the additional time and manpower required to abstract the theories behind TensorFlow into a standalone library.

So, What’s the Catch?
Clearly, Google is creating tremendous value for the broader machine intelligence community by releasing TensorFlow, but what do they get out of it? First of all, they will receive invaluable feedback, testing, and contributions from thousands of developers and scientists around the world. TensorFlow as a library will improve at a rate that would be impossible within Google only.
Second, there is an important caveat – the version of TensorFlow released to the public can only run on one computer, not across thousands of machines linked in parallel such as happens in practice at Google. The result is that while Google can get feedback on the core algorithms of TensorFlow, it does not expose itself to any existential risks of an enterprise-level threat emerging based on these tools. Additionally, the AI algorithms are only one small piece of the puzzle of putting together and end-to-end operable system – Google isn’t giving away the secret sauce to its massive hardware infrastructure and all of its related innovations.
Additionally, by open sourcing TensorFlow, Google is helping to enrich the broader community and potentially accelerate projects that will become major clients of Google Cloud services in the future. It’s far better for Google that these projects will be based on TensorFlow instead of rival platforms.
Finally, this will all serve as a recruiting tool for future Google engineers, especially among the machine learning and AI community of academics who are more willing to work on projects with a significant open source or community angle.
Strategically, Google will always try to stay a few years ahead internally of what it releases to the public. However, TensorFlow is an extremely welcome shift for Google’s approach to in-house algorithms that will hopefully lead to exciting startups and projects in the years to come.
I’ve heard from some of my pals who use ML professionally that this could be a game-changer. I can’t help but wonder why the market didn’t provide a tenable solution prior to Google releasing theirs.