
ReCaptchuring Value
Very annoying; very useful.
As science progresses, and the gap between what humans and computers are capable of narrows, we have become increasingly anxious to prove our differentiation. It’s a well-worn science fiction trope to have robots (computers) masquerading as humans; and because humans
The robots of tomorrow are the bots of today, serving their creators for benign or malicious reasons alike. For many organizations, these bots can cause serious harm to their businesses. From the early days of Ticketmaster’s web presence, they have had to deal with automated scalpers buying up all available tickets in pairs of 2, milliseconds after their release. To help slow the bots down, they turned to technology like CAPTCHA. CAPTCHA, which stands for “Completely Automated Public Turing test to tell Computers and Humans Apart”, was first invented in 2000 by Luis von Ahn, a Guatemalan computer engineer. The early version of the test looked like an Etch-a-Sketch traced over children’s building blocks: seemingly random strings of alphanumerics designed to be easy for humans to decipher, but hard for computers.

These would act as virtual gateways, admitting real humans and denying bots. The technology was simple, effective, and free. It took off. By the mid-2000s, over 200 million CAPTCHAs were being solved every day worldwide. Von Ahn remembers being very proud of this fact, at first; but his pride soon gave way to a sobering realization: those 200 million CAPTCHAs were essentially being discarded as waste. “Each test takes on average 10 seconds to complete, which means humanity as a whole was wasting around 500,000 hours a day typing these annoying CAPTCHAs… and then I started feeling bad”, von Ahn quipped in his TED talk in 2013. Von Ahn realized that the very ability gap he was exploiting between humans and computers could have a use in digitizing books.
At the time, projects to digitize books were underway all over the internet. The primary technology for this was called Optical Character Recognition, or OCR. OCR is good at recognizing modern fonts with bright, highly contrasting pages; but older books that are either damaged, handwritten, uneven, or in some way irregular, present a lot more problems for the technology. Von Ahn’s major insight was to let the OCR learn from humans by sending words with low confidence intervals into the ‘test’ pool, which is kept separate from the ‘control’ pool. The control group are made up of words with numerous successful (consistent) human identifications that are used to anchor the ReCAPTCHA. One of these is shown at the same time as a ‘test’ word, like below:

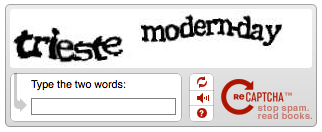
The user isn’t informed which is which, and so has an incentive to guess both of them correctly, since only one will unlock the website feature or page they are looking to access. Once the other word has been successfully guessed several times, it (depending on confidence interval) will either be put in the control pool or simply returned to the OCR with an answer.
Google saw the potential of the program in 2009 and purchased the revised ReCAPTCHA technology from Von Ahn. As of 2013, when von Ahn gave his TED talk, around 350,000 websites were using ReCAPTCHA, including some of the most popular (Facebook, Twitter, Ticketmaster, to name a few). Through these websites, users are deciphering roughly 100 million words a day at an accuracy rate of 99.1%, which translates into around 2.5 million books completed per year.
This is really cool.
Always been annoyed by the CAPTCHA, but I guess we dealt with it because it served a security purpose. Knowing that it is at least re purposing my wasted effort on the back end makes it a little less annoying. I wonder what other applications there are? Someone wrote a post on DuoLingo and how they were using their language learning app to crowdsource translations, maybe there is a similar extension here?