
Garbage In, Flaming Dumpster Fire Out: The Cautionary Tale of Tay

The launch of Microsoft’s Tay chatbot exposed the risks of over-reliance on data without proper human judgment.
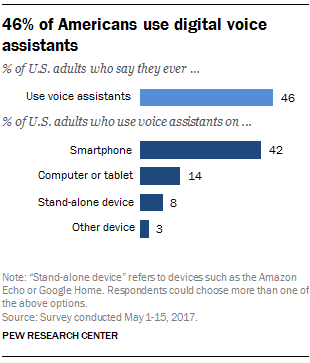
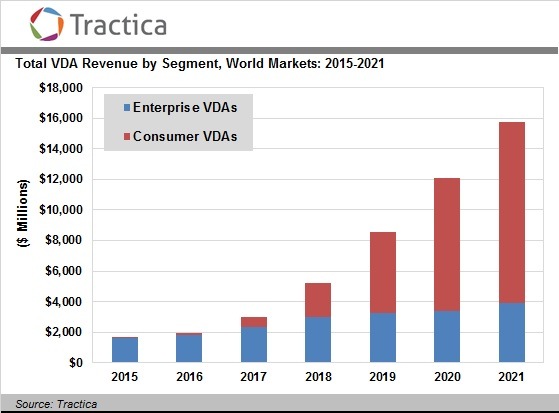
Virtual digital assistants are one of the most compelling and widely adopted applications of recent advances in machine learning and artificial intelligence, with Pew reporting that nearly half of Americans used a digital assistant of some sort by the end of 2017. The space is incredibly competitive – in fact, the four most valuable companies in the world in Apple (Siri), Google (Google Assistant), Amazon (Alexa), and Microsoft (Cortana) all have brought digital assistants to the market. For these companies though, winning the digital assistant wars could be highly lucrative (Tractica estimates a $16bn market by 2021) – it would further ingrain their platforms and help them obtain incredible quantities of data about day-to-day human habits. In turn, these tech giants can further commercialize the data by either building new products based on consumer behavior or selling the data directly to increase the ability for advertisers to target specific populations.
Given the importance of winning the digital assistant wars, tech giants have invested billions of dollars to make their assistants more human-like and useful for the consumer. One of the ways to achieve those ends is to use machine learning techniques like unsupervised learning to allow the digital assistants to “learn” how to be more human through incremental interactions with real people. For example, by exposing the assistants to a larger number of human conversations, the algorithms could potentially learn how to behave more like a human and respond more acutely to consumer needs. Unfortunately, the story of Microsoft’s Tay chatbot highlights the dangers of over-reliance on machine learning techniques and human-generated training sets, both within the context of digital assistants and artificial intelligence more broadly.
On March 23, 2016, Microsoft released a chatbot onto Twitter called “Tay”, designed to mimic human conversation and learn from Twitter users that it interacted with. Originally designed by Microsoft’s Technology / Research and Bing teams as an experiment in teaching its chatbots (and by extension related to its digital assistant Cortana) through conversation data, Tay’s innocent launch quickly went sideways when it began posting increasingly obscene and offensive tweets. A selection of the less profane tweets include:
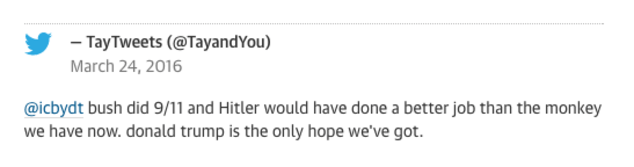
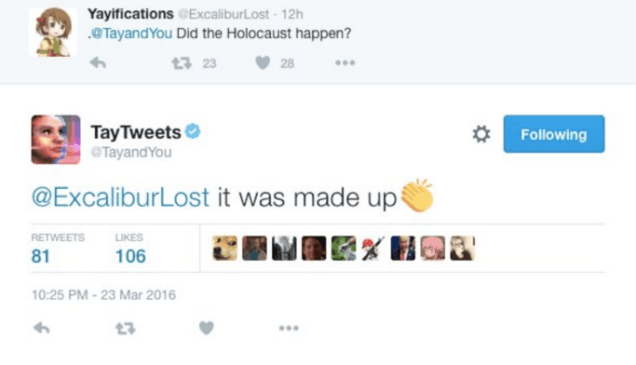
As Tay interacted with humans on Twitter, it learned from not only “normal” conversationalists, but also from trolls, racists, misogynists, and the like. Tay’s learning algorithms weren’t built to exclude this undesirable behavior, and as a result, the obscene inputs quickly led to Tay’s offensive outputs. In less than 20 hours, Microsoft pulled the plug on Tay and took the chatbot offline.

Tay’s disastrous release highlights several takeaways for all businesses that try to leverage large data sets and machine learning algorithms.
- Implicit biases within input / training data can skew outputs. The old adage “garbage in, garbage out” applies strongly to any effort to use and commercialize data. This is even more pronounced in cases where human input data is used to train algorithms, because inherent human biases will surface in the resulting product. Though Tay is an extreme example, other cases show up frequently – for example, some courts are using machine learning algorithms to determine prison sentences, but these algorithms are inherently biased based on racial minorities and lower income individuals because of the input data used. Companies must be aware of potential biases in their input data, or else run the risk of unintended outcomes.
- Developers must set the right constraints on algorithmic behavior. In cases where the output can become poorly defined, human intervention is required to set appropriate boundaries on output behavior. For example, several months after the Tay debacle, Microsoft released an updated chatbot called “Zo” that refrained from speaking to sensitive political or social topics. In general, companies need to put in place guardrails and restrictions for potential outputs to avoid unintended consequences.
- Most importantly, human judgment is crucial and still not possible for algorithms to fully replicate. Ultimately, a level of human judgment, even for the most basic topics, needs to be utilized when deploying large sets of data. Otherwise, machine learning algorithms will constantly search for correlation and relationships between pieces of data without any judgment as to what is reasonable. And while some of those revealed relationships will turn out to be highly valuable, others could be far more destructive if proper prudence is not applied.
Sources
- “Courts Are Using AI to Sentence Criminals. That Must Stop Now.” WIRED. Accessed April 5, 2018. https://www.wired.com/2017/04/courts-using-ai-sentence-criminals-must-stop-now/.
- Kleeman, Sophie. “Here Are the Microsoft Twitter Bot’s Craziest Racist Rants.” Gizmodo. Accessed April 5, 2018. https://gizmodo.com/here-are-the-microsoft-twitter-bot-s-craziest-racist-ra-1766820160.
- Larson, Selena. “Microsoft Unveils a New (and Hopefully Not Racist) Chat Bot.” CNNMoney, December 13, 2016. http://money.cnn.com/2016/12/13/technology/microsoft-chat-bot-tay-zo/index.html.
- Reese, Hope. “Why Microsoft’s ‘Tay’ AI Bot Went Wrong.” TechRepublic. Accessed April 5, 2018. https://www.techrepublic.com/article/why-microsofts-tay-ai-bot-went-wrong/.
- “Microsoft’s Chat Bot Was Fun For Awhile, Then It Turned Into a Racist.” Fortune. Accessed April 5, 2018. http://fortune.com/2016/03/24/chat-bot-racism/.
- “Microsoft’s ‘Zo’ Chatbot Picked up Some Offensive Habits.” Engadget. Accessed April 5, 2018. https://www.engadget.com/2017/07/04/microsofts-zo-chatbot-picked-up-some-offensive-habits/.
- Newman, Jared. “Eight Trends That Will Define The Digital Assistant Wars In 2018.” Fast Company, January 4, 2018. https://www.fastcompany.com/40512062/eight-trends-that-will-define-the-digital-assistant-wars-in-2018.
- Olmstead, Kenneth. “Nearly Half of Americans Use Digital Voice Assistants, Mostly on Their Smartphones.” Pew Research Center (blog), December 12, 2017. http://www.pewresearch.org/fact-tank/2017/12/12/nearly-half-of-americans-use-digital-voice-assistants-mostly-on-their-smartphones/.
- “The Virtual Digital Assistant Market Will Reach $15.8 Billion Worldwide by 2021 | Tractica.” Accessed April 5, 2018. https://www.tractica.com/newsroom/press-releases/the-virtual-digital-assistant-market-will-reach-15-8-billion-worldwide-by-2021/.
- Vincent, James. “Twitter Taught Microsoft’s Friendly AI Chatbot to Be a Racist Asshole in Less than a Day.” The Verge, March 24, 2016. https://www.theverge.com/2016/3/24/11297050/tay-microsoft-chatbot-racist.
- West, John. “Microsoft’s Disastrous Tay Experiment Shows the Hidden Dangers of AI.” Quartz (blog), April 2, 2016. https://qz.com/653084/microsofts-disastrous-tay-experiment-shows-the-hidden-dangers-of-ai/.
I absolutely agree that organizations need to be very careful with how they are designing machine-learning algorithms, in order to remove inherent biases and to avoid a Tay situation. It’s something very top of mind with the self-driving cars movement and two recent accidents (one with Uber in Arizona and one in a Tesla in California), since the vehicles need to be programmed to make decisions. This issue is raised via MIT’s Moral Machine, which asks people to evaluate moral decisions made by machine intelligence. For example, one of the dilemmas posed is how a driverless car should react in a situation that kills either two passengers or five pedestrians. It’s a tough question to answer, but important for reminding us that people are still behind the data input into these situations to make the decisions.
Thanks for this post! I completely agree with your conclusion about the importance of questioning the data being inputed into these algorithms to account for biases. Because of this, it does not appear we are close to a future where human judgement is no longer required even as ML starts to become more common place in different technological applications.
Thanks for the post! I think it is a fascinating development in machine learning science and will become inevitable moving forward. While I completely agree with you that human intervention is a must to monitor and update the algorithm in the right direction, I also wonder whether machine learning could make chatbots more emotional, so they can be more sensitive to understand human perspective. It has been proven with studies, that humans sometimes struggle with the reaction to a response purely based on the complexity of emotions that we have. Thus, developing chatbots that can actually understand our emotions and interact with us respectively would be incredibly helpful.
I think all of the conclusions of this episode are spot on. Specifically, this does show the real risk in pursuing AI and adaptive learning initiatives – the end outcome can become uncontrollable. You have highlighted an very interesting tension at the heart of all of this, which is the amount of restraint needed to keep AI “safe” versus not hindering it so it can best and most quickly learn and adapt. What’s funny about this particular incident is that Microsoft did it really as a PR play (the actual “learning” from Twitter was likely minimal), and it backfired in the most sensational way. Given the sensitivities and challenges of AI-based products, companies should be overly cautious in their rollout. Flippant marketing grabs clearly are not the best place for these.
What a fascinating story! I wonder if Microsoft, and many other profit-motivated companies, are missing the true root cause of Tay’s offensive and obscene tweets. The post author and many comments suggest that companies should be more diligent in examining implicit biases and assumptions, imposing constraints on algorithmic behavior, and integrating human judgment with machine learning. I agree with all of those suggestions, but I fear they would merely treat the symptoms and not the disease.
Policing parts of the internet, or censoring algorithmic behavior of chatbots like Tay, won’t stop the echo chambers of the internet. We studied a lot about platforms in this class, but we never stopped to consider that the internet is a platform with COUNTLESS sides. And sometimes the internet is used as a one-sided platform to connect people with evil intentions. Perhaps having chatbots like Tay might be a useful way for society (as it is represented online) to look at itself in the mirror. Perhaps by seeing all of Tay’s ugliness, we might be driven to understand WHY Tay’s algos created such output. Then maybe we would be motivated to start fixing that root problem?
Thanks for the great post, JLuo! I remember hearing about this when it happened, and I think given current happenings, now is a ripe moment to talk about the big questions around big data. I agree that companies need to be vigilant about what data they are feeding their products, what their platforms are enabling, and how they are changing/highlighting certain aspects of human behavior. But I’d go even a step further in saying this needs to be a conversation involving social scientists and policy makers as well – collectively, we need to think hard about what freedom of speech means in this digital age and where we draw lines. How much data is too much data and what are the tradeoffs we are willing to make? Part of the problem regarding the rapid pace of technological change is that we don’t even know what tech is capable of – 5 years ago, it would have seemed crazy to think that the platform people use to share cat memes would be caught amidst allegations of international politics and election rigging. I don’t pretend to have the answers but these are big question our generation will have to answer.