
Crowdsourcing AI at Drift: Does Analyzing Crowdsourced Information Actually Make Bots Smarter?

The proliferation of chatbots over the last two years has made life easier for some people. But are these bots really learning from their crowdsourced data inputs to make the outcome better for all users?
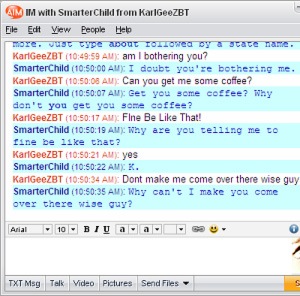
Chatbots and artificial assistants have seen a proliferation over the last two years. Remember SmarterChild from our AIM days? Think of that, only much smarter. Companies like Drift, a B2B product that uses artificial intelligence to allow companies to provide smart customer service, is one of the 10,000+ bot companies that have sprouted over the last 5 years to help take over some human tasks. Putting aside fears about whether or not artificially intelligent robots are here to take over – they probably are, embrace it – these bots are actually versions of crowdsourced platforms that get smarter the more people use them. But are they actually getting smarter? Or is this a benefit to one side of the platform more than the other?


How does it work?
 AI? ML? What’s going on here. These buzzwords are being thrown around with high frequency lately, but their subtle differences are important. Artificial intelligence is the medium through which a computer can respond to humans, a bot, responding from either from a set of pre-programmed answers or from a more open field of information. Machine learning, on the other hand, is the ability for computers to get smarter dynamically as it receives more inputs.
AI? ML? What’s going on here. These buzzwords are being thrown around with high frequency lately, but their subtle differences are important. Artificial intelligence is the medium through which a computer can respond to humans, a bot, responding from either from a set of pre-programmed answers or from a more open field of information. Machine learning, on the other hand, is the ability for computers to get smarter dynamically as it receives more inputs.
Both are impressive pieces of technology that have seen tremendous breakthroughs over the last several years, and companies are starting to monetize bots off of the spike in use of messaging applications. In its earliest form, chatbots respond to messages that users send with stock answers from a closed domain of information. They have a range of questions they can answer, and then they usually route the person asking questions to a human once they can no longer satisfy requests.

{kind=link}
In a more advanced form, chatbots can interact with humans in what is known as the “generative model” by answering a range of questions, even having a full-fledged conversation without the need of human intervention. This is only possible once a bot is smart enough to know how to respond to any and all types of statements. That intelligence is the result of deep learning a bot can be programmed to do through something called artificial neural networks, layers upon layers of data that get processed, sequentially, to make these bots autonomously smarter.
As Drift states, “this [kind of interaction] requires more than brute force computing: You need pattern recognition, and intuition. And those aren’t things that a computer can be explicitly programmed to have — they’re things a computer has to learn.” The computer can only learn this by ingesting more data.
Value Capture
Right now, the value capture structure of this model reflects the simplicity of B2B SaaS platforms. Drift sells its services to enterprises who pay per license or seat at the purchasing company. Consumers are able to utilize this service for free, and Drift captures even more value by collecting invaluable data from those users.
Value Creation
Drift sits at the intersection of two sides of the marketplace as a node. On one side, Drift sells its chatbots to large enterprises like Segment and Hubspot to power their customer service experience through a variety of messaging platforms, including Slack and FB Messenger. On the other side, Drift is the recipients of millions of crowdsourced datapoints from users making requests of their chatbot. In theory, the value proposition is that the more data Drift receives, the smarter the bots can be in answering those customers’ questions, which in turn means more satisfied customers. Value is derived for both the users, who have a better user experience, and for Drift, which can create an increasingly smart piece of technology that satisfies their B2B customers.
As a result, users are incentivized to engage in conversation with these bots to help answer their questions and solve their problems, knowing that the more they do so the better the answer they will receive. Furthermore, the crowd will begin to have fewer choices for outlets they can use to get in touch with customer service agents. Need to speak to someone from Comcast? You’ll be routed through a chatbot rather than having to talk on the phone. Users will benefit from this crowdsourced information making chatbots smarter whether they actively choose to do so.
Where the crowd falls short
How Drift’s technology actually works right now makes the value creation from crowdsourcing more nuanced. In its current state, the chatbot is able to answer simple, pre-programmed answers to questions. Its engineering team works manually on the back end to use data inputs from the crowd of people using the bot, and make tweaks to the algorithms by adding answers to new questions they see frequently. Although the size of the crowd of people interacting with Drift increases, meaning the amount of information provided to the company makes ML more likely, most bots aren’t exactly “there” yet in terms to completing the virtuous cycle of more information leading to smarter technology.
Below reveals a frustrating conversation between a Drift bot and a human in which Drift’s AI is not yet intelligent enough to handle the user’s question, despite it not being the first time the bot has received this request.
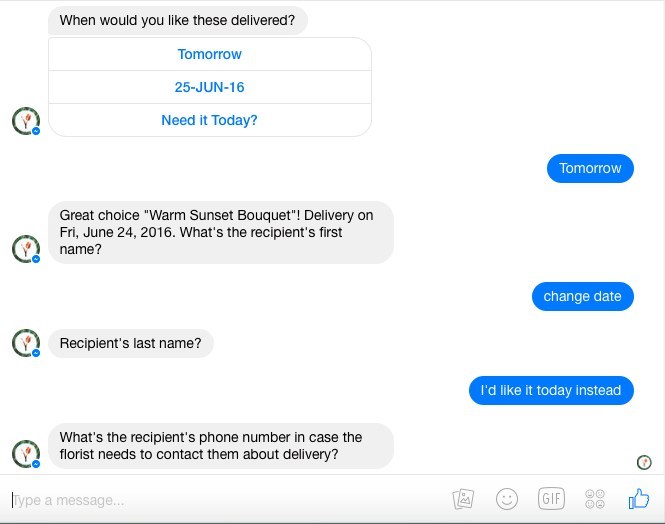
Although supposedly crowdsourcing answers to these questions will make these bots smarter, for now the technology falls shy of where it needs to be in order to ingest and learn from the data it receives. While companies like Drift are working feverishly on their ML by utilizing data they receive from the crowd, it is yet unclear whether users who interact with these bots on a frequent basis see the benefits of this crowdsourced information.
Sources:
- https://blog.drift.com/chatbots-infographic/
- https://blog.drift.com/machine-learning-explained/
- http://www.wildml.com/2016/04/deep-learning-for-chatbots-part-1-introduction/
- http://www.businessinsider.com/drift-is-a-chat-bot-that-gets-new-customers-2016-8
- http://venturebeat.com/2016/10/23/8-predictions-for-a-i-and-bots-in-the-next-24-months/
- https://blog.drift.com/all-about-chatbots/
- Primary source: Engineer from Drift
- http://bostinno.streetwise.co/2016/07/29/drift-ceo-on-customer-growth-using-ai-to-improve-marketing/
Great post! I’m glad you wrote about this because there really has been so much public discussion lately on the major challenges of chatbots and other “smart” programs. It’s interesting you find the main barrier to be the ML technology itself – with so many ML applications popping up in every industry right now, it’s hard to suss out whether the major barrier to making ML truly usable and accessible is the technology itself or the quality of the data or the sheer volume of data (likely a combination of all). I listened to an a16z podcast recently that argued that startups with a relatively small dataset (as compared to a Google or Facebook) can actually do a lot with ML on the data; it really comes down to having the RIGHT data, applying the optimal type of learning technique based on your domain and use case, and building the right purpose-built stack on top of it. Sounds like Drift will have to figure all of these out, on top of perfecting the actual ML technology itself.
Thanks for sharing Ellen. I’m would think that if Drift focuses on customer service it can get closer to have a smarter chatbot for that particular use case since it will be getting so much repetitive data. However, I wonder if Facebook, Google and the other bigger companies that collect way more data from all different contexts could end up pushing Drift out of their own niche just by getting smarter faster.