
What’s your alibAI: rise of recidivism reducing robots

In a small county in northern England, a police constabulary is taking the first faltering steps to outsourcing their recidivism decisions to a machine. Can machines do it better than humans, and who decides if they should be allowed?
Mike Barton is the charismatic Chief Constable of Durham Constabulary, a police organisation in the north of England overseeing County Durham and its c.524,000 inhabitants [1]. He has two big problems: the first, he can’t seem to deter offenders from committing new crimes. The second, his budget is shrinking whilst the population is growing.
In 2016 there were 21,354 criminal offences committed by people on bail for a previous offence in County Durham. Efforts to reduce numbers have consistently failed – as shown below, the Durham reoffending rate has stayed around 30% for the last ten years in which data are available, whilst for England and Wales as a whole the rate has actually increased from 35.5% to 42.0% [2]. At the same time, national funding has fallen by 19% in real terms from FY10/11 to FY18/19, driving a related workforce reduction of 18%. County Durham was one of the worst forces hit, facing a real terms funding reduction of 22% [3].
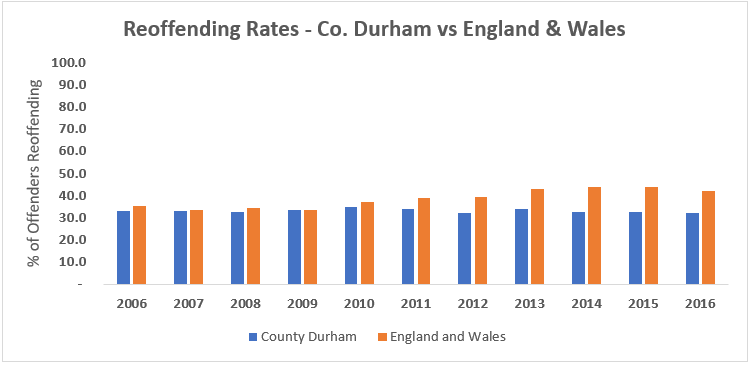
Source: UK Ministry of Justice (2018)
Barton is turning to machine learning as a possible solution. Other UK forces are trialling such solutions across the ‘value chain’ of police activity as algorithmic decision-making can consider vastly higher quantities of evidence than a human could manage. A system called VALCRI is being piloted by West Midlands Police to conduct crime analytics and answer questions typically reserved for a detective – how, why, when, and by whom was a crime committed? [4]. Kent Police are trialling the PredPol system widely used in the US which seeks to predict geographical areas where crime is likely to occur [5,6].
Durham Constabulary’s foray into machine learning is a cornerstone of its recidivism prevention program Checkpoint. In conjunction with the University of Cambridge they are developing an algorithm known as the Harm Assessment Risk Tool (HART) to identify offenders for placement into the program as an alternative to prosecution [7,8].

HART uses random forest forecasting to classify offenders into high, moderate, or low risk groups for reoffending. The forecast considers both the likelihood of the individual to reoffend, and the expected seriousness of the offence. A multiplicity of unique regression trees based on 34 input variables output a ‘vote’ on which group an offender should be classified into, which is subsequently weighted to sum to a final decision on how each individual should be categorised. Weightings are determined based on the potential error type – conservatism is built into the model so that, for example, the algorithm is more likely to erroneously classify a low risk offender as high than vice versa, since the reverse situation would be regarded as more dangerous [8].
The first trial of the system resulted in an overall accuracy of 62.8%, although it appears to have performed better on an error-weighted basis as it only made ‘very dangerous’ errors (that is, erroneously classifying a high-risk individual as low risk) in 0.73% of cases (see below for full results) [9]. The question for Chief Constable Barton is whether to roll-out machine learning more widely in the medium term, and how much faith his officers should place in the system. 62.8% may not seem like a sufficiently high success rate, but how does this compare to the next best alternative – a human?
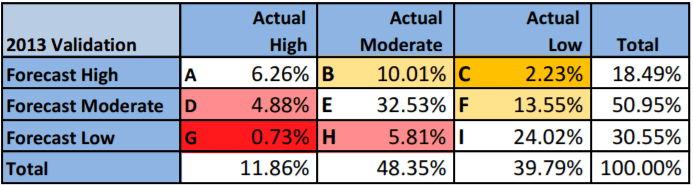
Source: Urwin, S. (2016)
Data has not been published on the algorithm’s success rate vs police officers, but Barton has stated there is “not a big difference” [10]. He remarks this sheepishly to a question about the algorithm’s efficacy, but one could also read his statement to say that the first iteration of this algorithm has proved itself roughly as effective as a group of trained police officers.
To the contrary, recent evidence from pilots in the US suggests that Durham Constabulary needs to be wary in its implementation. Whilst PredPol claim that their system has led to measurable improvements where it has been implemented [6], a recent academic study suggests the popular COMPAS system used for assisting bail and sentencing decisions is no more accurate than a group of random humans [11].
Durham Constabulary is deploying an algorithm which removes the onus from police officers of making a difficult decision which the data suggests they don’t get any better at over time. Chief Constable Barton should be lauded for finding new ways to ‘do more with less’, but given the lack of public engagement, limited evidence of efficacy, and no signs of a regulatory framework, he has gone too far. There are important open questions here which must be resolved publicly: will it ever be just to rely on machines for a decision which removes a person’s freedom? Or is it indeed unjust not to use the machine, if it is provably more reliable than a human?
[776 words]
—
References
[1] Durham County Council, “About us”. Available here (accessed November 2018).
[2] UK Ministry of Justice (2018) “Proven reoffending statistics: geographical data tool”. Available here (accessed November 2018).
[3] UK National Audit Office (2018) “Financial sustainability of police forces in England and Wales 2018”, HC 1501.
[4] Revell, T. (2017) “AI detective analyses police data to learn how to crack cases”, New Scientist, 3125. Available here (accessed November 2018).
[5] Ferris, G. (2018) “Home Affairs Select Committee: Policing for the Future inquiry supplementary evidence”, Big Brother Watch. Available here (accessed November 2018).
[6] PredPol, Inc., “Proven Crime Reduction Results”. Available here (accessed November 2018).
[7] Durham Constabulary, “Checkpoint”. Available here (accessed November 2018).
[8] Oswald, M., Grace, J., Urwin, S. and Barnes, G. (2018) “Algorithmic risk assessment policing models: lessons from the Durham HART model and ‘Experimental’ proportionality”, Information & Communications Technology Law, 27(2): 223 – 250.
[9] Urwin, S. (2016) “Algorithmic Forecasting of Offender Dangerousness for Police Custody Officers: An Assessment of Accuracy for the Durham Constabulary Model”, unpublished thesis, University of Cambridge.
[10] Barton, M. (2018). Oral evidence to The Law Society of England and Wales’ Technology and the Law Policy Commission. Available here (accessed November 2018).
[11] Devlin, H. (2018) “Software ‘no more accurate than untrained humans’ at judging reoffending risk”, The Guardian. Available here (accessed November 2018)
Great article! It’s really interesting to see how this system could be implemented in the future. To answer your question, I don’t think it would be just to rely solely on a computer, especially in the near term, given how each case is unique. I also believe that the grounds for an appeal would increase when an algorithm is used for sentencing, since in the near term there will be a significant chance of an error. I think this could function more as a tool for a police officer or judge rather than the sole sentencing mechanism. Additionally, it would be useful to track the differences in the sentences given by the officer and the algorithm as a way to identify any potential biases.
Wow I really loved your article, thank you! It’s so neat to see how ML is being used in all different kinds of industries and places.
I am concerned about how leaving decision making to machines will affect our future society. As much as humans will ‘check’ or ‘overlook’ things, at some point we will become dependent on machines and trust them to make the right decision (i.e. not paying attention in driverless cars).
In this case, however, it seems that the data is being used just for forecasting purposes. What happens after an offender is put into the ‘high, moderate, or low’ group for re-offending? Are they watched differently? Sentenced differently? If the machine in this case is just being used to save time for police officers and has an equal if not better success rate, I think it’s fine to go with the machine. If this data is then being used in ways that would seriously impact either the offender or the public, then I would be much more cautious and want more human integration in the decision making process.
On a personal note – a team in my practice at Accenture worked with the West Midlands Police (https://www.accenture.com/us-en/success-transforming-west-midlands-police) on analytics solutions for body-worn cameras so I used to hear a bit about this – love these worlds colliding!
Thanks! It’s a great point about use of forecasting, which is the case here. Offenders who are put into the ‘moderate’ category are admitted to the Checkpoint program which takes them through things including rehabilitation and civil service. They are given this as an alternative to prosecution, potentially ending in a jail sentence. So it is indirect, but the machine is informing a decision which leads to some people avoiding jail – that for me is the ethical grey area.
There was a big team from my group at KPMG who were on that same program with WMP, small world!
The challenge with this is that we don’t know who are building this algorithms. With COMPAS, at least, we do not have an visibility into the types of machine learning algorithms being used. There is no transparency and accountability in these algorithms. Computers are not wise. Everything they know are taught by our biases. And I worry that if we don’t check our computers, just like we need to check ourselves for biases, then these might prove riskier than we thought.