
Barrick – mining data for gold

Traditional hard rock mining has nearly reached its limits of efficiency. Data mining is coming to the rescue with machines learning how to extract the most value.
Gold mining started more than 5,000 years ago1 and has been historically a conservative industry where miners relied mostly on skills and experience. Currently, most of the gold is produced by industrial giants such as Barrick, the largest gold miner in the world, with more than 150 tons of gold churned out in 20172. Given its scale, global presence and more than 25-year expertise, Barrick is one of the leading companies in terms of technological development – most of the company’s operations are highly automated (see Exhibit 1 for images of automated control over the operations) and the company continues to pursue full process automatization in the coming years. However, the recovery in processing gold ore remains around 86-92%2 meaning that the remaining 10% of the mined gold is being lost during the extraction of gold from the ore. This implies that out of almost 20 mln tons of ore processed annually 2 mln tons are yielding zero output despite the salient costs of mining these 2 mln tons associated with excavating 10 mln tons of rock. Fortunately, there seems to be a way to address this issue with the advance of data storage and machine learning technologies.
Exhibit 1 – examples of Barrick’s control room and available real time data [Source: Barrick public materials3]
 Gold processing stage consists of the set of complex mechanical and chemical processes aimed at the extraction of gold from surrounding other materials – usually gold content is only 2-3 gr per ton of ore processed. Every operation (see Exhibit 1 for processing stage illustration) during this extraction process is regulated by multiple control parameters such as mills loading, temperature and pressure in flotation tanks, an intensity of applied reagents (cyanide, sulfites, acids, etc.) and others.
Gold processing stage consists of the set of complex mechanical and chemical processes aimed at the extraction of gold from surrounding other materials – usually gold content is only 2-3 gr per ton of ore processed. Every operation (see Exhibit 1 for processing stage illustration) during this extraction process is regulated by multiple control parameters such as mills loading, temperature and pressure in flotation tanks, an intensity of applied reagents (cyanide, sulfites, acids, etc.) and others.
Exhibit 2 – example of gold mining process stages [Source: Barrick public materials3]
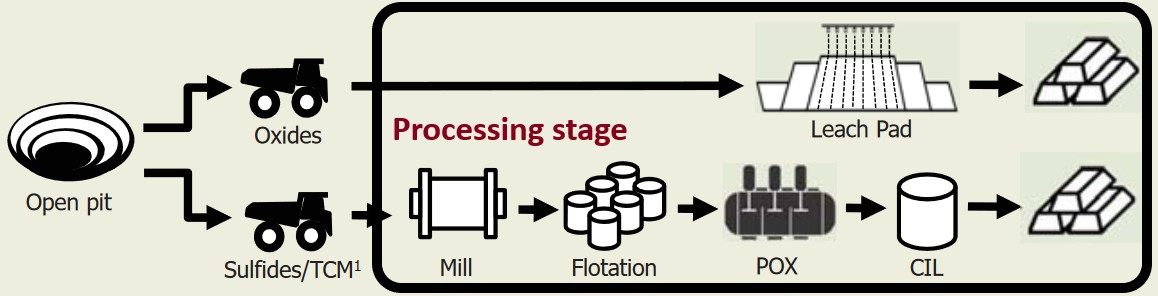

Currently, each of these parameters, although automatically monitored and most often remotely controlled, is set by operators who are prone to multiple human errors, biases, and drawbacks comparing to machines, most common of which are:
- linear extrapolation of trends – e.g. if an increase of pressure increases gold output then plant operator tends to increase it to the maximum. In reality, however, the laws of nature are often non-linear and the optimal point could be not at the extreme
- risk aversion – operators are incentivized based on the previously achieved recovery rates and could be disinclined to risk KPI target in favor of slightly more optimal decision with a huge downside threat
- slow and often late, retroactive decision making – it takes weeks for plant employees to assess the resulting output from chosen set of parameters which may be already irrelevant to the ever-changing chemical properties of processed ore
In short, the processing plants employees are overburden with “routine” type decision making which is, however, too difficult to formalize in “if-then” type of algorithms. In turn, machine learning approach to the issue could benefit from the ample amount of available historical data, a constant relationship between control parameters and output variable and opportunity to train algorithm for optimal parameters to reach maximum gold output.
Barrick’s management has already indicated the launch of Barrick Data Factory, but the current actions are aimed primarily at the low hanging fruits from the simple automation fixes and elimination of safety concerns based on the predictive analytics. To source more fresh ideas the company attracts data scientists and organizes annual hackathons. However, the focus of the technological advancement remains is still vague and allocating a special team solely for the processing optimization with machine learning could yield significant results in terms of gold output at minimal investments compared to capex-heavy equipment upgrades and new deposits development. Moreover, machine learning technology employed for the plants’ control could later incorporate not only production optimization but also solve for the minimal costs (power, components, materials, etc) and therefore unlock previously unprofitable processing opportunities.
However, if Barrick chooses to start developing these technologies the company risks to spend funds on unsuccessful R&D while the competitors could later try to copy or buy the winning technology and save money on its development. The risk of the first-mover technological advancement is further exacerbated by unforeseen risks in the implementation, including the processing lines halts, and retraining of the employees that could be costly.
[709 words]
Endnotes
[1] US Geological Survey “Gold” by Harold Kirkemo, William L. Newman, and Roger P. Ashley https://pubs.usgs.gov/gip/prospect1/goldgip.html
[2] Barrick’s 2017 Production Report https://barrick.q4cdn.com/788666289/files/quarterly-report/2018/Barrick-Mine-Stats-2017-Q4.pdf
[3] Barrick’s public presentations and press-releases: “Driving change”, March 5, 2018 https://www.barrick.com/news/news-details/2018/driving-change/default.aspx; Investor Day Presentation, February 5, 2018 https://barrick.q4cdn.com/788666289/files/presentation/2018/Barrick-Investor-Day-2018.pdf
[4] BCG research, “Mining Value in AI”, October 5, 2017 https://www.bcg.com/publications/2017/metals-mining-value-ai.aspx
[5] Harvard Business Review Digital Articles, “How to tell if machine learning can solve your business problem”, November 15, 2016
Your point on the first-mover advantage and risk is well-taken, particular given the high R&D costs associated with leading the way in innovation. Such innovation could definitely prove to be a radical, rather than incremental, shift in the industry, but might be a short-lived competitive advantage, particularly if no patents could be acquired. I think this lends credence to the idea that tech firms (such as IBM with Watson) may fill in the gaps with AI and machine learning capabilities which can be generalized to multiple industries, including mining. In the meantime, Barrick may have to continue harvesting the lowest hanging fruit, rather than investing heavily in uncertain technology (particularly given Watson’s mixed track record thus far).
Thanks for your comment. Your point on IBM Watson is spot on – they actually partnered with another huge gold miner, Goldcorp: https://blog.goldcorp.com/2017/03/03/ibm-watson-gaining-new-exploration-insights-through-artificial-intelligence/ The only downside I see in this type of partnership is that it usually doesn’t provides a complete buy-in from the company’s employees which is essential for this type of disruption.
It is interesting for me to see a traditional industry like mining adopting next-gen technologies in their operations. It seems from the paper that you might think that instead of going for low-hanging fruit, the company should consider taking a bigger leap with its applications of machine learning. Without knowing too much about the industry, one of the applications that I wonder about is using machine learning to first identify gold deposits, and then predict reserves and/or mining pathways that would optimize for costs and revenues.
I liked this post and agree that AI can offer a lot of benefits, especially seeing that currently many of the decisions are taken by humans just based on their based estimates. The only challenge I see with this is how to accurately link the change of the different parameters (variables in the machines) to the actual gold output. Since the input is probably not always the same (different levels of gold in the ground, different density, other materials in the ground, etc.), I assume that for different situations the optimal setup of a machine might be different. And Im not convinced that you can accurately assess in what kind of situation you find yourself using only machines. I guess my question would be: would AI work accurately in a setup in which the input is not always the same?
Great post. Improving metallurgical recovery rates remains a key challenge to the mining industry. That 10% is a big hole in the sack if we consider the enormous capital and time effort to find, develop and run a large scale Barrick-style gold mine. Incorporating machine learning seems today a must-have complementary tool for engineers to try maximize recoveries, especially when treating more complex orebodies or using unconventional extraction techniques (e.g. sulfide leaching). One thought — would the algorithms work better if they were feed with data from multiple mining operations and not just the one they are trying to optimize for? Maybe the algorithms could “train” better if learning also from patterns found in similar gold mines in their respective districts or in other parts of the world. Barrick as an operator of multiples sites globally could then find “data synergies” with this approach.
This is a great post. I didn’t realize how much of the gold is lost during extraction. I find it fascinating that there are places in the gold mining supply chain where a company can implement ML-powered strategies to reduce waste but are hesitant to do so. The article sights that mining companies are worried of being the first mover because competitors will copy or buy the technology. I would imagine that ultimately the algorithm is only as good as its data. If a competitor doesn’t have the same pools of data, then the competitor will not be able to fully copy the tech. I wonder if there are other factors making mining companies hesitant to roll this technology fully.